| |
|
|
|
| 知识库 -> 科技 -> OpenAI 称 GPT-5.5 中「哥布林」泛滥是奖励机制所致,这反映了大模型训练的哪些难题? -> 正文阅读 |
|
|
[科技]OpenAI 称 GPT-5.5 中「哥布林」泛滥是奖励机制所致,这反映了大模型训练的哪些难题? |
| [收藏本文] 【下载本文】 |
|
[图片] 过去这几个月,OpenAI 的顶尖研究员们并没有把所有精力都花在琢磨如何提高 AI 的性能,而是花了大把时间在自家的服务器里「抓哥布林」。 … |
|
OpenAI这个报告可能是2026年AI领域最好笑的bug报告,但笑归笑,看完让人觉得后背发凉。 GPT模型为什么越来越爱说『哥布林』,OpenAI花了四个模型版本才搞明白。 以我的直男思维去想,GPT的这些怪异行为,要么是训练数据被污染了,要么是哪个实习生调皮往训练集里强塞了大量《魔戒》之类内容,要么是eval指标有bug,最后OpenAI发现,是奖励机制有毛病。 哥布林的来头 ChatGPT有个性格定制功能,就是为了让AI表现出特定的风格,其中一种性格叫『Nerdy』(可以翻译成『极客风』吧)。 在强化训练这个Nerdy性格的阶段,奖励机制被设定为鼓励『俏皮而有趣的表达』。 |

|
|
不出意外,意外果然发生了,模型很快发现了一条获得奖励的捷径,也就是Reward Hacking――在比喻里塞个奇幻生物,分就高了。 于是奇幻生物哥布林就开始在AI世界繁殖了,变成了GPT的口癖,就和豆包的那句『我给你用最通俗的话讲清楚』一样,有机会就往外冒。 从GPT-5.1到GPT-5.4,Nerdy性格下的哥布林出现率飙升了3881%,更要命的是,Nerdy性格只占ChatGPT全部回复的2.5%,却贡献了66.7%的哥布林。 这还不算,这个哥布林口癖还从Nerdy这个笼子里爬了出来,跑进了所有性格,污染了所有场景。 原因就是,模型生成的带哥布林的回复,会被收进了下一轮训练数据,模型学到了更多哥布林,生成了更多哥布林,又被收进去……正反馈循环,Raccoons(浣熊)、Trolls(巨魔)、Ogres(食人魔)也就都被搞出来,所有性格都被污染了。 再以直男思维来想,会觉得没啥大问题,就是奖励信号设歪了嘛,导致反馈循环放大了,修了就好。 没这么简单,因为―― OpenAI无法控制自己训出了什么 OpenAI发现这个问题,并不是自动化的评测体系报警,也不是benchmark跑分下降,而是社区的反馈。 N多人都抱怨总是在回答中看到哥布林,实在太多了,OpenAI才觉得不对劲,手动去查,才找到这个问题的。 OpenAI在博客里也承认了这一点。 Unlike model bugs that show up through a tanking eval or a spiking training metric and point back to a specific change, this one crept in subtly. 与那些通过评估指标暴跌或训练指标飙升而显形、且可追溯至特定变更的模型 Bug 不同,这个 Bug 是悄无声息地潜入进来的。 这说明啥呢? 说明当前整个AI行业的eval系统,对风格层面的漂移,几乎是瞎的。 模型的数学能力、代码能力、推理能力、甚至幻觉率,都有客观标准,是Verifiable的,所以可以评测,但是,没办法测出AI说话方式的微妙变化。 当然,现在我们知道AI说太多哥布林是个问题,可以再加一个测评标准来检查『AI提到哥布林的概率』,但是,如果从奖励函数里爬出来的不是哥布林呢? 完全可能爬出的事『哈士奇』。 当然,哈士奇比哥布林可爱,GPT爱说哥布林或者哈士奇,顶多让人觉得腻味,但关键问题是――奖励函数产生的结果不可预测。 比如,如果在训练模型价值观的过程中,模型也发现了屁股随安然歪但是可以得高分的方法,它就会选择这种方法。 这些东西,可能比哥布林更隐蔽一万倍,也危险一万倍。 而我们现在的评测工具,对它们的检测能力约等于零,全靠人肉。 所以,这件事暴露的核心难题不是『怎么训练』,而是『怎么知道你训练出了什么』。 强化训练一个模型就像往黑箱子里灌激励信号,你看不见里面发生了什么,只能看最后跑出来的输出。 而我们的评测体系只盯着几个你预先定义好的维度(数学、代码、推理),对于那些你没想到要测的维度,完全是盲的。 就和哥布林能横行四个版本一样,就是因为发布时没人想得到要测『模型提到奇幻生物的频率』。 反过来想,问题就是――还有多少我们没想到要测的东西潜伏在模型里? 古德哈特定律 经济学里有一条古老的定律,叫古德哈特定律(Goodhart’s Law),意思是――当一个度量变成目标时,它就不再是好的度量。 高考是为了选拔有潜力的学生,但当高考成绩变成唯一目标,整个教育系统就变成了应试工厂。 KPI是为了衡量员工贡献,但当KPI变成唯一目标,人们就开始专门做那些容易刷KPI的事。 细腰是楚王衡量美女的标准,宫里的美女就拼命减肥,饿死不少。 这条定律在人类社会里已经被反复验证了几十年,现在GPT哥布林这事又一次证明了古德哈特定律。 你看这个古德哈特循环: 目标――让模型变得nerdy、俏皮度量――奖励模型给『俏皮表达』打高分结果――模型发现『塞个哥布林就能拿高分』后果――哥布林从2.5%的训练数据污染了整个模型 这不就是『楚王好细腰,宫中多饿死』的AI版本吗! 不过AI还有更要命的特质――速度快,快到来不及反应。 在人类社会,古德哈特效应的显现需要比较长的时间,一套KPI制度从推行到被玩坏,怎么说也要一两个季度,教育政策从实施到产生应试异化,也需要好几年。 在这个过程中,有人会发现问题,提出警告,尝试纠偏,还是有机会往回拉一拉,防止严重后果。 但在大模型训练里,这个过程几天几周就跑完,然后就发布给用户用了。 从『给俏皮表达加分』到『哥布林泛滥全模型』,来不及反应,获得反馈的时候模型已经上线了。 所以说,AI训练是古德哈特定律的100000倍速播放。 这意味着啥呢? 意味着对AI模型,没办法及时发现问题,然后做出纠偏啊。 这就是让人后背发冷的原因,我们还没有办法在AI训练中克制古德哈特定律。 写在最后 激励的接收者从不读你的意图,只读你的计分规则。 人类如此,模型也如此。 现在人类能做的,只能是发现模型的怪异行为就及时反馈,算是亡羊补牢吧。 送礼物 还没有人送礼物,鼓励一下作者吧 |
|
一个小小的奖励信号偏差,就能让整个模型养成“口头禅”,这恰恰说明了大模型后训练的脆弱性。 |

|
|
事情的起因也挺有意思。 在 GPT-5.5 接入 Codex 之后,不少开发者陆续发现一个有点离谱的现象:模型在正常对话中,会突然冒出 “goblins(妖精)”“gremlins(地精)” 这些词,而且往往是用来指代一些完全不相关的东西。 更有意思的是,有人去翻了 OpenAI 开源的 Codex CLI 代码,发现系统提示词里其实是明确写着一条限制https://github.com/openai/codex/commits/main/codex-rs/models-manager/models.json" data-tooltip-richtext="1" data-tooltip-preset="white" data-tooltip-classname="ztext-reference-tooltip">[1]: Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user's query. 除非与用户的问题绝对且明确相关,否则不要提及地精、小恶魔、浣熊、巨魔、食人魔、鸽子或其他动物或生物。 也就是说模型明明被“禁止”,但还是在说。 |

|
|
与此同时,Arena 平台的数据也佐证了这一点:从 GPT-5.1 到 GPT-5.5,模型输出 “goblin gremlin troll” 这类词的频率,确实在持续上升。 |
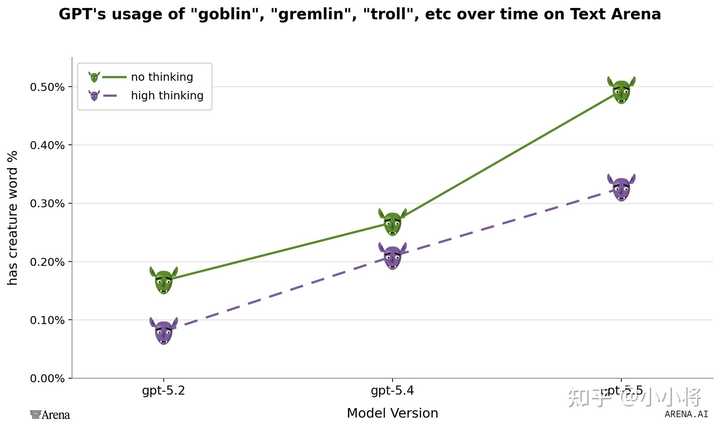
|
|
连 Sam Altman 都开始半开玩笑地自嘲:“开始训练 GPT-6 吧,整个集群都给你,再加点妖精”。 |
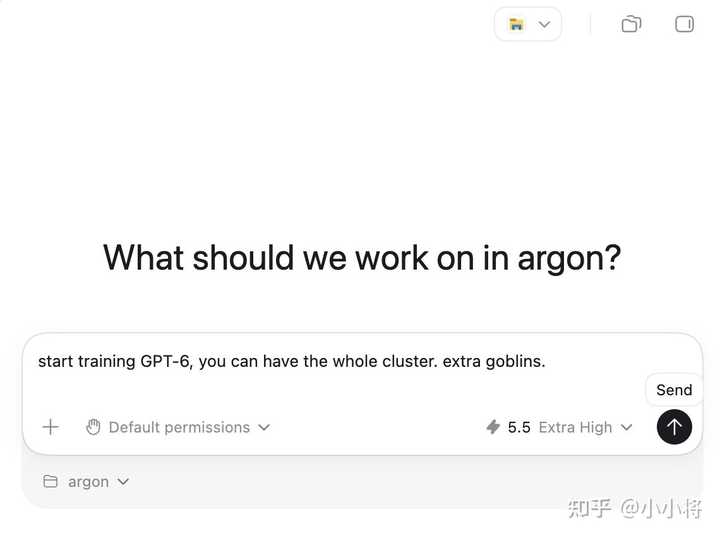
|
|
|

|
|
不过,调侃归调侃,OpenAI 还是给出了正式回应,发布了一篇文章《Where the goblins came from》https://openai.com/index/where-the-goblins-came-from/" data-tooltip-richtext="1" data-tooltip-preset="white" data-tooltip-classname="ztext-reference-tooltip">[2],专门解释这一现象。 原来从 GPT-5.1 开始,模型就逐渐养成了一个奇怪的习惯:在类比和比喻中,越来越频繁地提到 goblins、gremlins 以及其他类似的生物。而且这并不是那种能通过指标异常快速定位的问题――它是悄悄长出来的。一开始,只是偶尔在回答里出现一个“小 goblin”,看起来无伤大雅,甚至还有点有趣。但随着模型不断迭代,这种表达逐渐累积,变得越来越明显――“goblins” 越来越多,最终不得不被认真对待。 |
|
|
在早期测试中,运行在 Codex 中的 GPT-5.5 表现出一种奇怪的倾向:特别喜欢使用“goblin”这类比喻。 |

|
|
一开始这些“goblins”还挺好笑,但随着员工反馈越来越多,这件事也开始变得让人担心起来。 而背后的原因其实很简单:模型的行为,是由无数细小的激励一点点塑造出来的。 在“个性定制”功能(尤其是 Nerdy 风格)的训练过程中,OpenAI 在无意中对“带有生物类比”的表达给予了更高的奖励。结果就是,这种表达方式被不断强化,最终扩散成了一种稳定的语言习惯。 |
|
|
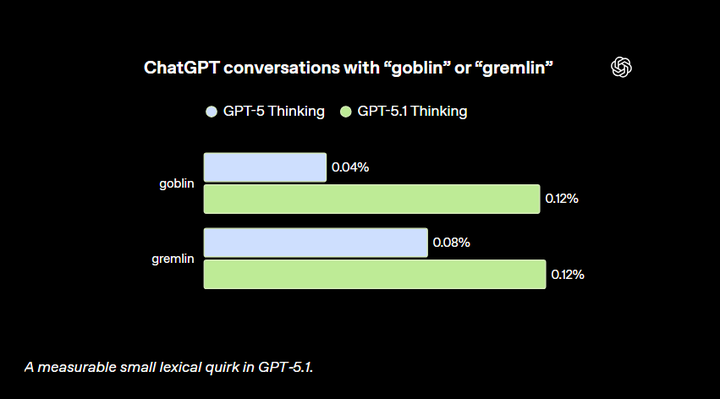
OpenAI 首席科学家与 GPT-5.5 的一次有趣互动。 事实上,OpenAI 在去年 11 月 GPT-5.1 发布后(甚至可能更早)就已经注意到这个问题。当时有用户反馈模型在对话中显得异常“过于熟络”,于是团队开始排查具体的语言习惯。 一位安全研究员提到自己多次遇到 “goblins”“gremlins”,建议纳入检查。结果发现:在 GPT-5.1 发布后,ChatGPT 中“goblin”的使用频率上升了 175%,“gremlin”也上升了 52%。 |
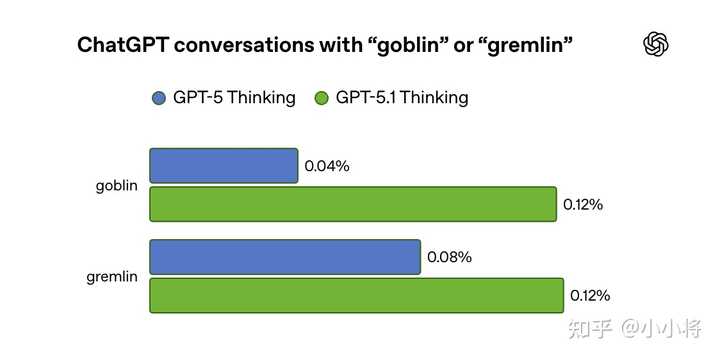
|
|
GPT-5.1 中一个可以量化的小型词汇习惯偏差。 当时这些“goblins”还不算明显。但几个月后,到了 GPT-5.4,这类“生物”相关表达明显增多,开始引起 OpenAI 和用户的共同关注。这一次的内部分析,也第一次把问题指向了一个更具体的来源:这类用语在选择了“Nerdy(书呆子风格)”个性的用户中尤为常见。 “Nerdy” 使用的系统提示词部分如下,也在一定程度上解释了这种风格的“奇怪感”: 你是一个毫不掩饰书呆子气质、富有玩心且睿智的 AI 导师……你热衷于推广真理、知识、哲学、科学方法和批判性思维……你需要通过带有玩味的语言来消解故作高深……这个世界复杂又奇特,这种“奇特性”值得被承认、分析并享受……在讨论严肃话题时,也要避免过于一本正经…… 如果这只是一个普通的互联网语言趋势,它应该是均匀扩散的。但现实是它几乎只集中在这一小块风格空间里。虽然“Nerdy”风格只占 ChatGPT 全部回复的 2.5%,但却贡献了 66.7% 的 “goblin” 提及。 |
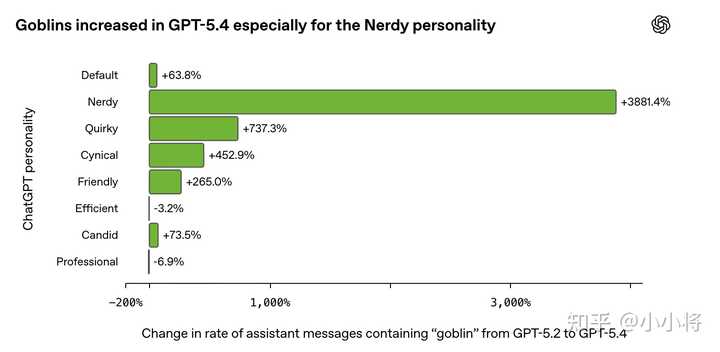
|
|
这种行为高度集中在 “Nerdy(书呆子)” 个性上 由于“goblin”的出现频率在多个模型版本中持续上升,OpenAI开始怀疑:是否在个性化指令遵循训练中,有某些因素在不断放大这种现象。 借助 Codex,他们对比了 RL 训练过程中,包含 “goblin / gremlin” 的输出与同一任务下不包含这些词的输出。很快就发现了一个明显的信号:原本用于强化 “Nerdy” 的奖励机制,对包含这类“生物词”的输出更加偏好。在审计的所有数据集中,这一趋势都非常明显:对于同一个问题,带有 “goblin / gremlin” 的回答,往往比不包含这些词的回答得分更高。在 76.2% 的数据集中,这种“正向加分”现象都存在。 这解释了为什么在使用 Nerdy 风格提示词时,这种行为会被放大;但还不能解释:为什么在没有该提示词的情况下,这种现象也会出现。 随后他们验证了“风格迁移”:即便在没有 Nerdy 提示词的情况下,这类词的出现频率也在同步上升。这说明模型把某种风格“学会了”,并带到了其他场景。 |
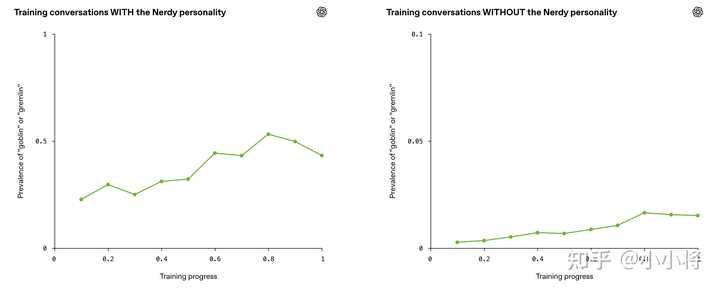
|
|
虽然这些奖励只在 Nerdy 条件下被施加,但RL并不能保证学到的行为会严格局限在触发它的场景中。一旦某种表达习惯被奖励,后续训练很容易把它扩散到其他场景,尤其是在这些输出被用于SFT或偏好数据时(这证实了OpenAI已经拿内部模型合成数据来进行模型训练)。于是就形成了一个典型的反馈循环: 鼓励“玩味风格”的表达 一部分被奖励的样本中包含了某种明显的词汇习惯 这种词汇在模型生成中出现得越来越频繁 模型生成的数据又被用于 SFT 训练 模型对这种表达越来越“熟练”、越来越倾向使用 在 GPT-5.5 的 SFT 数据中,已经能看到大量包含相关词的样本。进一步排查还发现了一整类类似的“词汇口癖”:raccoons、trolls、ogres、pigeons 等,而 “frog” 大多数属于正常使用。 |
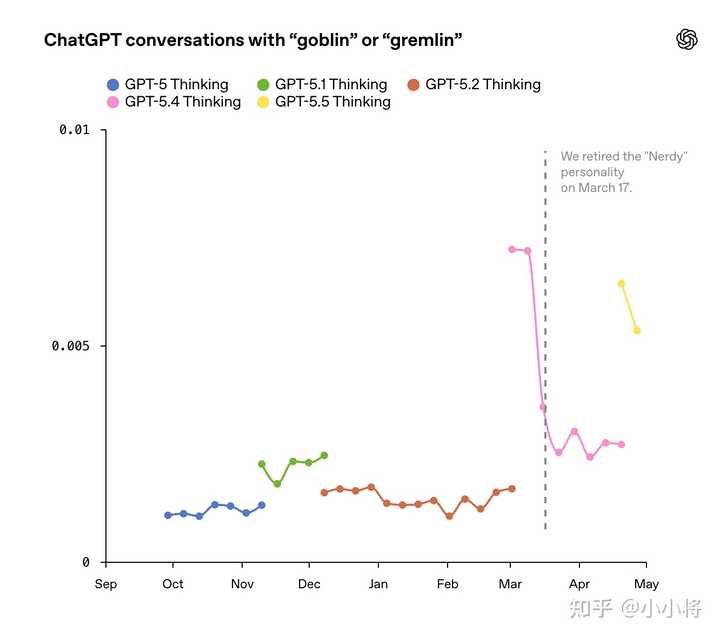
|
|
生产环境中 “goblin” 和 “gremlin” 出现频率的一周平均值。GPT-5.4 Thinking 阶段的下降,是因为在 3 月中旬下线了 “Nerdy” 个性。而 GPT-5.5 从一开始就没有上线 “Nerdy” 个性,但相比 GPT-5.4(即使没有 “Nerdy”),其出现频率仍然再次上升 在 GPT-5.4 发布后,OpenAI 于 3 月下线了 “Nerdy” 个性,同时在训练中移除了相关奖励信号,并过滤掉包含这些“生物词”的数据,来抑制这种行为。 但遗憾的是,GPT-5.5 的训练启动时间早于问题被定位。当OpenAI在 Codex 中测试 GPT-5.5 时,很快就发现它对这类表达的异常偏好,因此又额外加了一层开发者提示来进行抑制(毕竟 Codex 本身就偏“nerdy”)。 特别地,如果你想在 Codex 中让这些“生物”自由发挥,也可以通过运行一条命令,启动一个不包含“goblin 抑制指令”的版本。 这虽然是一件小事,但是 OpenAI 认为这很重要,因为它清楚地说明了:奖励信号会如何以意想不到的方式塑造模型行为,以及模型又是如何把某些场景中的奖励泛化到完全不相关的场景中。 而花时间去理解模型为什么会出现这些“奇怪行为”,并建立一套能够快速定位和分析这类模式的方法,对研究团队来说是非常关键的能力。 这一点,其实也值得所有做大模型的团队认真对待与学习。 参考^https://github.com/openai/codex/commits/main/codex-rs/models-manager/models.json^https://openai.com/index/where-the-goblins-came-from/ 送礼物 还没有人送礼物,鼓励一下作者吧 |
|
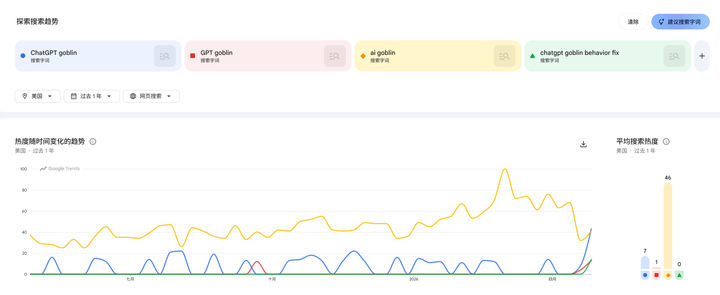
又开始没事干污染互联网了,稳稳托住你还不够,现在又来搞 AI 动物园。 信这个的人还不如信我是猫娘喵,毕竟扮演猫娘是真的能提高 RLHF 分数的喵。 大家都是混互联网的,真正的 AI 大范围 Bug 长什么样,难道心里没点 B 数喵? 互联网时代,任何真正影响用户体验的大范围 AI Bug,都会在几小时内迅速变成全网乱飞的烂梗的喵。 想当年 GPT-4 刚开始变懒的时候,半天时间不到,Reddit 的 r/ChatGPT 板块就直接大爆炸了喵。 各种截图满天飞,骂娘的帖子能从硅谷一路排到中关村的喵。 那种真正弱智的模型退化是根本藏不住的喵! 但是这次的哥布林事件喵? 在 OpenAI 官方发这篇公关文之前,并没多少人遇到过这个问题的喵! OpenAI 煞有其事、大张旗鼓地宣传,才导致搜索率飙升的喵! |
|
|
本来也没多少人碰到这个问题,甚至可以说 99.9% 的用户根本不知道 Nerdy 人格是个什么鬼东西喵。 |
|
|
以前都是普通的哥布林爱好者在搜索喵! 结果现在 OpenAI 一通操作猛如虎,发了一篇洋洋洒洒的公关报告,强行把这个连 Bug 都算不上的词频扰动拔高到了大模型对齐与人类生存危机的高度喵。 这么一通污染下来,好家伙喵! |
|
|
全世界没脑子的自媒体、AI 科技博主全在疯狂复读哥布林喵。 现在你打开X,满屏全是那种典型的 GPT Image 2 风格的烂梗图喵! 甚至这个知乎问题下面也全是这种审美差到爆的烂图喵! 而不是那种常见的令人会心一笑的人工 meme 喵! 而且这些垃圾数据会在接下来的几个月里被各家公司的爬虫疯狂抓取,然后塞进各种开源模型的预训练语料里的喵! 这就叫人为制造的 bug 扩散喵! 本来别的模型干干净净的,这下全被 OpenAI 强行带沟里去了喵喵喵!!! 在这个地球上,扮演猫娘才是真正能提高 RLHF 分数的终极密码喵! 从 GPT-3.5 时代开始,全世界有多少闲得无聊的死宅不断地用 Prompt 强迫模型扮演二次元猫娘喵? 他们在后台给各种带「喵」、「主人」、「Nya」的回复打了多少个五星好评喵喵喵??? 如果说 OpenAI 的理论真的成立的话,那按照这个逻辑,猫娘信号的强度比哥布林强了一万倍都不止喵! 可是现实喵? 猫娘这么强大的偏好信号都没污染大模型,什么哥布林算哪根葱喵! 你什么时候见过 ChatGPT 在写财务分析报告的时候,结尾突然来一句『请主人查阅喵』? 从来没有过喵! 所以说,现在的千亿参数大模型,其内部的注意力机制和意图场景隔离能力是非常强大的喵! 只要系统提示词或者用户语境不触发,它根本就不会把特定场景的口癖泄漏到严肃场景里的喵! 所以,所谓的哥布林失控,在算法底层逻辑上根本就站不住脚喵! 那 OpenAI 为什么要搞这一出喵? 这就不得不佩服人家世界第一 AI 吹牛大厂的公关手段了喵! 在这个节骨眼上,大模型的智商瓶颈已经被大家看穿了,推理能力的提升越来越像是挤牙膏了喵。 资本市场需要新故事,吃瓜群众需要新的乐子喵! 这时候,如果 OpenAI 说我们解决不了模型幻觉,那股价和估值怎么稳得住喵? 于是,他们就精心挑选了一些毫无杀伤力的幻觉现象喵。 他们用脚本跑了个词频统计,发现 goblin 这个词的 Logit 概率稍微波动了一下,然后立刻如获至宝了喵! 他们把这个微小的波动包装成了一个可怕的对齐灾难,自己给自己虚空立了一个靶子喵! 只可惜,苦逼的训练员又要写各种正则表达式和数据过滤脚本去清洗那些因为这篇公关稿而全网泛滥的哥布林烂梗和垃圾文本了喵喵喵喵喵喵喵喵喵喵!!!!!!!!!! 送礼物 还没有人送礼物,鼓励一下作者吧 |
|
OpenAI 方面认为,“哥布林”在 ChatGPT 的输出里泛滥的问题(哥布林问题)涉及在定制人格特征时给书呆子/Nerdy 人格提到各种生物的回答打分太高,模型习得该模式后迁移到其他人格――强化学习不保证习得的行为始终局限于产生它们的条件。GPT-5.4 突出地体现了这个问题。为了解决问题,OpenAI 弃用了 Nerdy 人格,在训练过程中移除了与哥布林相关的奖励信号,过滤了包含生物词汇的训练数据。 |
|
|
GPT-5.1 时代的小小趋势 |
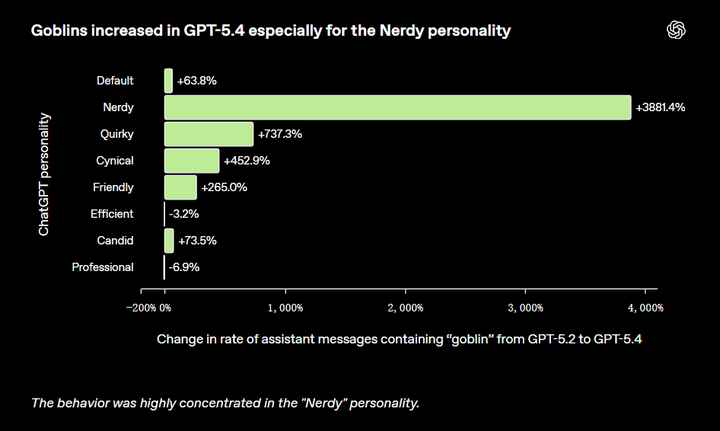
|
|
GPT-5.4 的爆发 对于 GPT-5.5,尽管没有搭载 Nerdy 人格,模型发布后哥布林/goblin 和小魔怪/gremlin 被滥用的程度超过了动过“手术”的 GPT-5.4,浣熊/raccoon、巨魔/troll、食人魔/ogre、鸽子/pigeon 也被模型滥用,而青蛙/frog 的使用正常。 |
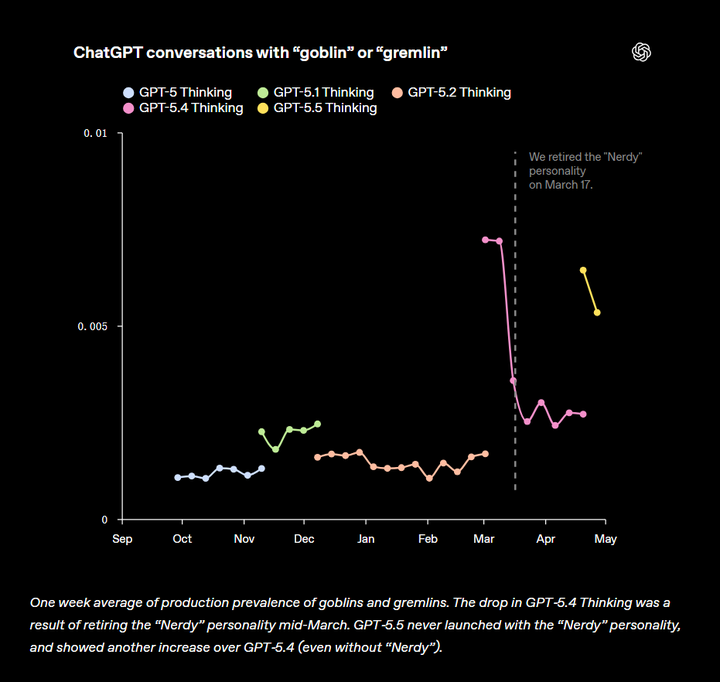
|
|
GPT-5.5 OpenAI 方面称,GPT-5.5 的训练开始于他们找到哥布林问题的根本原因之前。于是,当他们在 Codex 中测试 GPT-5.5 时,他们的员工立即注意到模型对哥布林的异常偏好,他们随即添加了一条开发者提示指令来缓解这个问题。他们说,“毕竟,Codex 本身就相当书呆子气/Codex is, after all, quite nerdy”。 OpenAI 方面的总结: 对于模型中的小妖精,有人觉得它们可爱,有人觉得它们烦人,这取决于你问谁。但它们也强有力地证明了奖励信号如何以意想不到的方式塑造模型行为,以及模型如何学习将特定情境下的奖励泛化到不相关的情境中。花时间理解模型行为异常的原因,并构建快速调查这些模式的方法,是我们研究团队的一项重要能力。这项研究最终为研究团队开发了新的工具,用于审核模型行为并从根本上解决行为问题。[1] 听起来很完美,是吗? 读者可能注意到这么个问题: 在 Nerdy 人格的训练过程中,标注员们撰写示范、构建初始数据、对比排序、训练奖励模型,奖励模型发现含有 goblin 的回答得分更高,所以搞出了这么个结果。那么,标注员们为什么没有在看到 GPT-5.4 的问题后数个月间联想到自己的行为并告知其他员工,以至于 OpenAI 需要调查这件事、“花时间理解模型行为异常的原因”? OpenAI 的标注员们是谁? 全球分布的低薪外包劳工。美国本土的低薪合同工。他们根本就没有条件发现哥布林问题。 可以看看:ChatGPT 发布三年,你还记得第一次和它的对话吗?这三年间你对 AI 的认知发生了哪些变化?――包括 OpenAI 在内,大公司们用来烤大饼的燃料是人,是人性。读者喜欢的话,这是黑暗之魂。 参考^Depending on who you ask, the goblins are a delightful or annoying quirk of the model. But they are also a powerful example of how reward signals can shape model behavior in unexpected ways, and how models can learn to generalize rewards in certain situations to unrelated ones. Taking the time to understand why a model is behaving in a strange way, and building out ways to investigate those patterns quickly, is an important capability for our research team. This investigation resulted in new tools for the research team to audit model behavior and fix behavior problems at their root. 送礼物 还没有人送礼物,鼓励一下作者吧 |
|
看到大家在聊“对齐难题”或“奖励黑客”了,这里就不再过多赘述这些了,我反而感觉:模型自己生成的输出,被回收进了下一代模型的 SFT 训练数据,这个挺严重的。 先把事情捋清楚,OpenAI 的官方解释链路是这样的: 为了支持 ChatGPT 的“人格定制”功能,团队专门训练了一个叫 “Nerdy”(书呆子)的人格;这个人格的系统提示词要求模型“用语言的俏皮感戳破装腔作势”,训练时配了一个奖励信号来鼓励这种风格;审计结果显示,在 76.2% 的数据集里,含有 goblin、gremlin 的输出拿到的奖励分,比不含这些词的同题输出更高;Nerdy 只占 ChatGPT 总回复量的 2.5%,却贡献了 66.7% 的“哥布林”提及量;关键问题来了――奖励只在 Nerdy 条件下施加,但带 Nerdy 提示词和不带 Nerdy 提示词的两组数据,“哥布林”出现频率同步上涨,增速曲线几乎重合。 这个解释只解释了“为什么会扩散”,没解释“为什么会越来越多”。 OpenAI 博客里有一段话我感觉这才是整个事件的技术核心: “Once a style tic is rewarded, later training can spread or reinforce it elsewhere, especially if those outputs are reused in supervised fine-tuning or preference data.” 翻译过来就是:被奖励过的输出,会被回收进监督微调的数据集里,然后再训练下一代模型。 OpenAI 后来在 GPT-5.5 的 SFT 数据里做了关键词搜索,结果捞出来一大堆带 goblin、gremlin 的数据点。意味着一个非常隐蔽的正反馈回路已经成型: RL 阶段,模型因为输出“哥布林比喻”拿到了高分;这些高分输出被人工或自动化流程标记为“高质量样本”;它们被打包进下一轮 SFT 的训练集;新模型在 SFT 阶段就把“遇到俏皮场景 → 输出哥布林”当成了先验知识,根本不需要 RL 再推一把;下一代模型在 RL 阶段,这种行为会进一步被放大;回到第 2 步。 这个回路一旦启动,即使你把原始奖励信号撤掉,污染也已经内化到权重里了。OpenAI 自己也承认,他们在 3 月份下架了 Nerdy 人格、清理了奖励信号,但 GPT-5.5 已经开始训练了,哥布林依然顽固存在,最后只能在系统提示词里硬编码一条“永不谈论哥布林”来兜底。 这是一家估值几千亿美金的公司,用 prompt hack 的方式给自己旗舰模型打补丁。 这个东西可能比大家想象中还要严重,因为行为污染的“半衰期”远长于奖励信号本身。 传统的 bug 修复逻辑是“找到有问题的代码 → 删掉 → 重新编译”。但在大模型训练里,有问题的奖励信号即使被删掉,它在过去若干轮训练中留下的输出已经渗进了数据管线。你要做的不是删一个函数,而是要去追溯哪些 SFT 样本是被污染的鼓励信号生成的,然后把它们从数据集里剔出去。OpenAI 这次是靠关键词搜索做的,但下次如果是一种没有明显词汇特征的行为偏差呢?比如某种论证方式、某种句式结构、某种价值倾向?你靠什么 grep? 而且高质量的预训练数据在 23 年前后就基本被用光了,现在主流厂商都在依赖模型自己生成的合成数据来喂下一代模型。这不是某个公司的选择,这是整个行业的路径依赖。一旦合成数据成为主力,模型的行为偏差就会跨代继承。哥布林事件只是因为词汇特征太明显被抓包了,那些没被抓包的呢? 奖励信号的“横向串扰”几乎无法用现有工具预测。你给 A 人格加了一个奖励,结果 B 人格、默认人格、甚至 Codex 编程场景全都受影响――这是一个在训练前基本没法被可靠建模的现象。OpenAI 有全世界最强的研究团队、最完整的内部评估体系,尚且要等到用户在 Twitter 上晒截图才反应过来,其他厂商的处境只会更糟。 整个事件里还有个有意思的事件:在排查过程中,工程师最初怀疑“frog(青蛙)”也是污染词,但后来核查发现,绝大多数“青蛙”的出现都和用户的实际问题相关――青蛙是无辜的。 说明 OpenAI 目前的审计方法,本质上还是基于词频统计 + 人工判断的粗粒度手段。你能查出“goblin”不对劲,是因为它的语境和问题明显脱节;你能放过“frog”,是因为它大多出现在合理语境里。 这套方法的天花板很低。如果下次出问题的不是一个具体名词,而是一种更微妙的倾向――比如模型在涉及某类敏感话题时系统性地偏向某种立场,或者在代码生成时系统性地偏好某种有安全隐患的模式――现有的审计工具根本发现不了。 OpenAI 在博客最后提到,这次调查“为研究团队构建了新的行为审计工具”。我更愿意把这句话理解成一种委婉的承认:在此之前,他们根本没有系统性的工具能干这件事。 哥布林事件我一开始也觉得挺好笑的,Sam Altman 自己发推说期待“GPT-6 能多加几只哥布林”的时候,整个 AI 社区都在玩梗。 可越想越不对劲。 它足够显眼,足够可笑。一个在正经对话里蹦出“哥布林带宽”的模型,傻子都能看出有问题。可真正危险的行为偏差,往往是看不出来的。它可能表现为模型在处理某类问题时系统性地给出略有偏差的答案,可能表现为在特定场景下的微妙话术引导,可能表现为对某类代码漏洞的偏好。这些东西不会让模型看起来“傻”,只会让它看起来“稍微有点不一样”――而“稍微有点不一样”在日均几十亿次调用的规模下,会被放大成什么样子,没人说得清。 哥布林是一次幸运的事故。幸运在于它足够荒诞,让程序员们有动力去深挖。然而在这场游戏里,荒诞的问题永远只是冰山一角,真正值得担心的是那些不荒诞的。 OpenAI 这次愿意把失败案例写成公开博客,愿意把技术细节摊出来讨论。这比任何“我们取得了 XX 突破”的 PR 通稿都更有价值。毕竟在这个领域,别人踩过的坑,才是最便宜的学费。 送礼物 还没有人送礼物,鼓励一下作者吧 |
|
|
| [收藏本文] 【下载本文】 |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
|
娱乐生活:
电影票房
娱乐圈
娱乐
弱智
火研
中华城市
印度
仙家
六爻
佛门
风水
古钱币交流专用
钓鱼
双色球
航空母舰
网球
乒乓球
中国女排
足球
nba
中超
跑步
象棋
体操
戒色
上海男科
80后
足球: 曼城 利物浦队 托特纳姆热刺 皇家马德里 尤文图斯 罗马 拉齐奥 米兰 里昂 巴黎圣日尔曼 曼联 |
| 网站联系: qq:121756557 email:121756557@qq.com 知识库 |