| |
|
|
| ֪ʶ�� -> �Ƽ� -> OpenClaw��������ʲô�أ� -> �����Ķ� |
|
|
[�Ƽ�]OpenClaw��������ʲô�أ� |
| [�ղر���] �����ر��ġ� |
|
OpenClaw����������ʲô�أ���ЩSkills��ֵ���õģ� |
|
�Ҿ���������Ҵ����ij��������Ϊ�ܶ��˶Դ�ģ�͵�ӡ��ͣ����һ���ı���Ȼ������Ի��ϡ����ǣ�������Ѿ���Ϥʹ�� Agent Coding������˵ Claude Code������Ҳ��������ر����档��Ϊ�ұ����������� Claude Code���Ҿ�����������һ��������������ά˹����������һ�� 24 Сʱ������Ӧ�Ĵ��˼���� Claude Code�����Ƕ��ڲ�����̵�����˵�أ������Ա��һ����Ȼ���Ա�� Agent ������������ �����������Լ��Ļش����������ҵĿ�������һ���ܽᣬ����ת���� ���� OpenClaw ����ɶ��һ����ͨ���˵� AI �ܼ�ʵ�� ��˵���������Ǹ����¼��µij���Ա��������̨ Synology NAS �� Docker��żȻ������ OpenClaw �����Ŀ������һ����ĩ������ȥ��Ȼ���ͣ�������ˡ� ����������һ����ʵ���õĹ��ܣ��������ڡ� ?? �ʼ��ܼ� Gmail �����ÿ������ 8 ���Զ�����δ���ʼ����ֺ���� Telegram����ЩҪ��������Щ�� newsletter����Щֱ�Ӻ��ԡ���Ҳ���ô� Gmail ��Լ��ٷ�δ���Ľ����ˡ� ��ʱҲ���������ֳ���һ�飺"���ҿ���������ʼ�"����ʮ�����ֺ����ȼ��� ?? �ճ�ͬ�� & ���� �ҹ�˾�÷��飬˽���� Google Calendar�����˸��Զ�ͬ���ű������������Ļ����Զ������� Google Calendar �ÿ����������Լ��Сʱһ�Σ��Զ����δ�� 24 Сʱ���ճ̣��쿪���˾� Telegram ��һ�¡� �����ٵ������ǻ��顣 ?? AI �����绰 �������ɧ�ġ����� Vapi.ai�������� AI ���Ҵ�绰�����綩�ͣ� "���Ҵ�绰��λ������6��룬5λ������" ��ֱ�Ӳ���ȥ�������ĸ�������ͨ��һ������Ϣ˵�꣬Ȼ��ش���������⡣ʡ���Լ���绰�� ?? �ڶ����ԣ�Obsidian + Notion �����һ�ʱ�����IJ��֡��ܹ��ǣ� Obsidian��˽��֪ʶ�⣩��ͨ�� Syncthing ���ͬ���������뷨���ʼǡ��زĶ��ӽ�ȥ Notion��������������ռǡ����͡��������� �� AI ����ʱ���˵"��¼һ��"�����Զ�д�� Obsidian �������Ƭ˵"�Ǹ��ռ�"�������ͼƬ�ϴ��� NAS ͼ����Ȼ���� Notion ����һƪͼ�IJ�ï���ռǡ� ��������Ҳ��ֱ��˵"�Ǹ����죺��ţ��"�����Զ�д�� Notion Task List ���������ࡣ ��ͳ֪ʶ������ ��Obsidianд�ʼ� �� ��Ŀ¼�ṹ �� �ֶ����ǩ �� �ٰ�ֵ�÷����İᵽNotion�Ű档����ϵͳ��ȫ���Ծ�������һ�ܺ�ͻķ��ˡ� ���ڵķ�ʽ�� ����Telegram˵�仰��תƪ���¡�������Ƭ��ʣ�µ�ȫ�Զ��� ? Obsidian��˽��֪ʶ�⣩����ɢ�뷨��ѧϰ�ʼǡ����Ͽ����ĺ������Զ��鵵��YAML frontmatter�Զ����ǩ��Ŀ¼�����Զ��ؽ����Ҳ���Ҫ��"����÷��ĸ��ļ���"����Thoth���жϷ��࣬�Ŵ����������Լ��ع�Ŀ¼�� ? Notion��������������ռ��Զ����ɣ�ͬһ��ϲ����ظ�������Ƭ�Զ���ͼ����Ƕ�룬�����Զ����ൽ��Ӧ��Ŀ��checkbox��뷢�������ݴ�Obsidian�زĿ�������������Notion��һ����·���ꡣ ? ����ϵͳ������Obsidian���زijغ�˼������Notion�dz�Ʒչʾ̨��������Obsidian�������Notion���м�İ��ˡ���������ʽ���������Ҷ��֡� ���ı仯����"����App��ά��һ��"�����"һ����ڣ�����ϵͳ�Զ�Э��"�� ����ֻ��Telegram�Ի��������һ������������֪ʶ��+һ����ʱ�ɷ�����Notionҳ�档ά���ɱ����㡣 ?? Ͷ����ϼ�� ���ܵ���������ϲ��ԣ��ƽ�/��ծ/��Ʊ/�ֽ�� 25%����ÿ��һ�Զ��������ʲ�ƫ��ȡ����� ��5% �� Telegram �澯������ƽ�⡣ƽʱ��ȫ���ö��̡� �������¼��� COE��ӵ��֤�������أ�ÿ�������Զ����ͽ���� ?? �������� ����Ʒ���ѡ�������������ʱ�Σ������ Telegram ��һ�³�ʲô���Լ���������Ч����Ҳû������ ?? �ļ�ת�� �����װ������ MarkItDown������ PDF/Word/PPT ��ȥ��ֱ��ת�� Markdown��arXiv ������ת��ι�� AI ��ժҪ�� ?? ��Ϣ�״� ��������һ�� Agent���� Huginn����ר������Ϣ�ռ����������� Agent �ܹ�����˾��ְ������ MCP ���ߡ� �ܽ� �����Ͼ��ǰ�һ�� API ����ͨ�� OpenClaw ������������Ȼ���Ե��ȡ�������һ��"���������"������һ��ס�� NAS ������ֹܼҡ����м��䡢���ճ̡��ܴ�绰����д�������ܰ��㶢�Ÿ������顣 ���ĸ��ܣ���"��ȥ��"�����"������"�� �ܶ���������飬˵һ�仰�㶨�ˡ� �����ż�����ͣ���Ҫ Docker ���� + ���� API key������һ�����������ز�ȥ�ˡ� �������һ���Ƽ���Typeless �������ճ� vibe Coding��������ʹ��� openclaw ȥ�ɻ���������Ѿ���һ��Ĭ�ϵ�ѡ���ˡ� ����Ŀǰ�Ҳ���������õ���������������֧���ƶ��˺� PC �ˡ� ����ٲ����ʵ��� |
|
|
|
|
|
������ ��û�������������һ�����߰� |
|
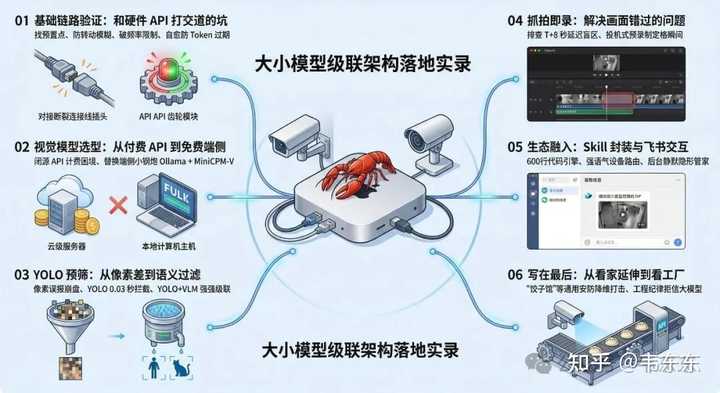
����һ��ʱ�� OpenClaw ֮������ͻȻ�뵽���ﱾ����������өʯ������ͷ��һ���ڿ������ޣ�һ������̨��è��Ϊʲô�������ǽӵ� OpenClaw �ϡ�өʯ�ƵĿ���ƽ̨ API ���������൱��֣�Token ��������̨���ơ�ʵʱץ����Щ���������ֳɵĽӿڣ�������Ӧ���ǿ��еġ����ϲ��� OpenClaw�� Mac mini 24 Сʱ���ߣ�������ģ�͵�����Ҳ�߱��� ��˵���ۣ��������Ѿ��ȶ�����һ���ˣ��������̻������� N �ι��̵�����Ч�����ȶ��������������֡��˶����Ƶ���������� YOLO Сģ��������Ԥɸ�ٵ����ض�ģ̬��ģ�����������⣬����Ϊ�˽����ʧ��Ҫ����������ع��˵ײ��ʱ���ᣬ�м侭���˺ü��ּܹ��Ʒ����ؽ���������ʽҲ�ӵ�����ָ���ѯ�����Ż����ˡ���̨��ĬѲ�ӣ����²����� + �쳣��ʱ���͡���˫ģʽ��ÿһ��Ҳ������ʵ��������֮�������⡢������⡢���Ż��Ĺ��̡� ��������Ȼ�Ǵӿ���è����Ҿӳ��������ģ����ײ�ļ�������ʵ�߱�ͨ���ԡ��칫������ֵ�ؼ�ء��������˿�����������ֿ�İ���Ѳ�죬ֻҪ�� IPC ����ͷ + ��Ե���� + ��ģ�����������������������Ƶļܹ���ʵ�֡�����ջ���漰�� YOLO Ŀ���⣨����Ԥɸ�������ض�ģ̬�Ӿ�ģ�ͣ��������⣩�����¼���ӳٵĹ��������ffmpeg�����Լ� OpenClaw �� Skill ��װ�ͷ���Ⱥ��Ϣ���͵ȡ� ��ƪ��ͼ˵����� өʯ�� API �ĶԽӲȿ��������߽硢�����ؼ�֡� YOLO ������ļ����ݽ���ʵ�����ݡ���ģ̬��ģ���ڶ˲ಿ�������Ȩ�⡢"YOLO Ԥɸ �� VLM ���� �� һƱ���"�ļ����ܹ������ʱЧ��ä����Ͷ��ʽԤ¼�ơ��Լ� OpenClaw Skill ��װ�ͷ��齻������������ʵ�֡� ���£�enjoy: |
|
|
ȫ�����ݵĸ���ͼ 1 ������·��֤����Ӳ�� API ���Ŀ� ʵ�ʶ���֮ǰ�����ȿ����˽�����өʯ�ƿ���ƽ̨�� API ��������һ˵һ��өʯ�Ƶ��ĵ��ڹ��� IoT �����������ò����ģ����Ľӿڣ�Token �������豸�б�����̨���ơ�ץ�ġ�ֱ������ַ��ȡ�����У������ߵ��DZ��� HTTPS + POST ģʽ������Ҫ����˽��Э�顣���֮�£�TP-LINK ����Ʒ�Ƶ�����ͷ�����ڶ�û�й����Ŀ����� API�������ֻ��������ץ�����ȶ��ԺͺϹ��Զ������⡣ |
|
|
https://open.ys7.com/cn/s/supportcenter ��һ�������ﲻͬ����ͷ����������Ҳ��Ҫ��ǰ��������ҷ��ڿ�����̨ CP1 ����̨����ͷ��֧��Ԥ�õ�Ѳ���ͷ�����ƣ���̨�� C2C �ǹ̶���λ��ֻ��ץ�ĺ�ֱ�������ܣ�û����̨������ζ�Ŵ�����������豸·�ɣ������漰��̨������preset/move��ptz/start����ָ��ֻ�ܷ��� CP1��C2C �յ���ֱ�ӱ����� |
|
|
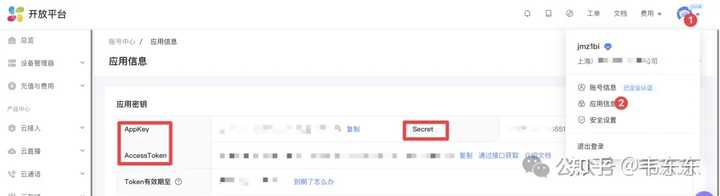
https://open.ys7.com/console/application.html API ���������֮���ҿ�ʼ�����ͨ������·��������̲��˼����ӣ����ⶼ�������������ã��Ժ����������ڻ��в�СӰ�졣 1.1 ��̨Ԥ�õ㣺APP ���Ҳ������ ��һ������Ԥ�õ���ô�衣���������Ȼ���Ǻܴ���̨����ͷ����һ�����䣬�����Ƕ�û�취�ܺõĸ���ȫ�����������Ҽƻ�������������Ԥ�õ㣬�ýű���������ͷ�������Ƕ�֮���л��������������������Ѳ�Ӹ��ǡ�����өʯ�� APP ��˺ü��飬ʼ��û���ҵ�Ԥ�õ��������ڡ� ����������ʵ��ȫ����Ҫ�� APP �������өʯ�Ƶ� API ������֧����̨������ƣ�ptz/start��ptz/stop����Ԥ�õ㱣�棨preset/add���������Ҹɴ�д��һ���ն˽���ʽ�ĵ��Խű� preset_wizard.py������֮��ֱ���ü��̷������������ͷת������ P ץ��Ԥ����ǰ�Ƕȣ�ͼƬ���Զ��� Mac �ϵ��������������˰� S ����ΪԤ�õ㡣��֧���л�"����ģʽ"��"��ϸģʽ"������ת�����ȣ���������������һ���ն�ң������ |
|
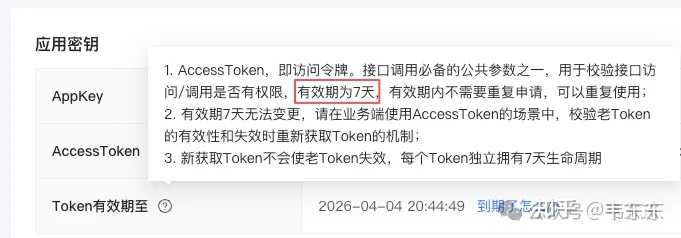
BTW��������дһ��С���Թ��߰�Ӳ��������ͨ��������ʽҵ����������ʵ�����漰�����豸����Ŀ��dz�ʵ�á�����ʱ���÷������ֻ��� APP ���������п��ƶ����ն�����ɣ�Ч�ʸߺܶࡣ 1.2 ��̨ת��λ֮ǰ��ץ�ģ�һƬģ�� �ڶ����ӱȽ����Ρ����� preset/move ����̨ת��Ԥ�õ��������̵���ץ�Ľӿڣ��õ���ͼƬ��һƬģ�����Ͼ���̨������ת����Ҫʱ�䣬��ûͣ�Ⱦ����ˣ��ij�������ͼ�����˶���Ӱ��ι��������Ӿ�ģ�ͷ��������˷������� �������ûʲô�ð취��ʵ������ preset_move ֮����� sleep 4-6 �������ͣ�ȡ��������Ұ�����ȴ�ʱ�����˻������� MOVE_WAIT��Ĭ�� 4 �룬ʵ�ʲ���ʱ���Ը�������ͷ�ͺ����� 1.3 ץ��Ƶ�����ƣ�ͬһ�豸 4 ���ڷ��ؾ�ͼ ����������ץ��Ƶ�ʡ�өʯ�Ƶ�ץ�Ľӿڶ�ͬһ�豸��Ƶ�����ƣ�����ץ�ļ������ 4 ��Ļ����ڶ��η��صĻ�����һ�ε�ͼƬ��������ĵ���û��д�����Dz���ʱ���� URL ��ȫ��ͬ�ŷ�Ӧ�����ġ� ������Ĵ�����ʽ���� capture() �����ڲ����˽�����ά��һ�� _last_capture �ֵ��¼ÿ���豸���ϴ�ץ��ʱ�䣬����ʱ�������������Զ� sleep ���롣 1.4 Token 7 ����ڵĽⷨ ���һ�����������ױ����Եģ�Ҳ��Ӱ�����ġ�өʯ�Ƶ� AccessToken ��Ч��ֻ�� 7 �죬����֮������ API ���ûᾲĬʧ�ܡ���������ֻ�Ƿ���һ�������� 10002 �� 10014���������������ϵͳ����һ��֮���ͻȻ�ҵ������ҿ���־��û�� crash �����֡� |
|
|
�ⷨ���� API ���õ���ײ�����������̽���Զ����ڡ�ÿ�ε�өʯ�ƽӿڣ������������ Token ������صģ����Զ���վ� Token���������롢���� Token ����ԭ���������������̶��ϲ�ҵ����ȫ���� �ⲿ�ֵ����ԭ���ǣ������й��ڸ����ƾ֤����������ײ����Զ����ڣ������ǿ��ϲ㶨ʱˢ�¡��������ҵ���дһ����ʱ����ÿ 6 ��ˢһ�� Token�����������ã���һ����ʱ����©�ܻ��߷��������ˣ�Token һ������ڡ������������� api() ��������ڸ�����ϵͳ���˵ף�����ʲôʱ����á����� Token ������ʲô״̬������������ 1.5 С�� ����ε�Ŀ����ǰ�����������·��ͨ��Token ��֤ �� ˫�豸��Ϣ��ѯ �� ��̨Ԥ�õ���� �� ץ�� �� ͼƬ���ء�û��ʲô�ر�ļ��ɣ���Ҫ�Ǹ�Ӳ�� API �ĸ��ֱ߽��������� 2 �Ӿ�ģ��ѡ�ͣ��Ӹ��ѵ���� ������·��֮ͨ������Ҫ����ľ������⻭������⡣����ͷ��ץ���ˣ��������Ĺ��ܣ������жϻ������Dz��DZ���Ȼ�����ѣ�������һ��Ļ��¼�����ձ���������һ����ģ̬�Ӿ�ģ��������ͼƬ���ݡ�ѡ�������Ⱥ������һ����Դ API �Ϳ�Դ���ز�������·�ߡ� 2.1 ��Դ������OpenRouter + Gemini Flash �Ϲ�أ��ȵ���Դ�콢ģ�͵� API ��ͨ������·���� to B ��Ŀ���ɵ�ϰ�ߡ�����һ����Զ�Ȳ��컨�壬������ baseline��ȷ��Ч����������֮����ȥ��ɱ��Ż��ͱ����������������õ��� OpenRouter �� google/gemini-3-flash-preview����Ӧ 2-3 �룬�ṹ�� JSON ���غ��ȶ���Ч��û���⡣ |
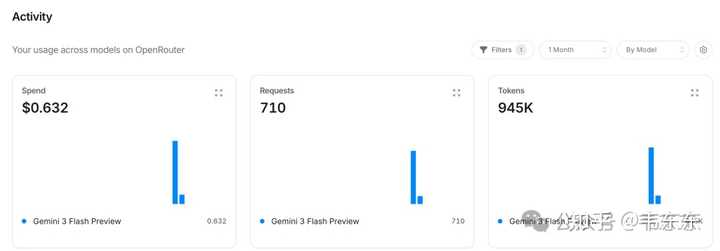
|
|
���ɱ���������̫�У�����Сʱ���Թ����о������� $0.632�����У�2 ���ӵ���һ�ε�Ƶ�����ۺϲ��˼���֮�������ģ�̫���� API �Բ�����̫���˼�ؾ���ʤ���ޡ������Ƶ���㣬һ�� 720 �ε��ã�һ��ʮ���飬һ���¼��ٿ飬��Ϊ�˿���������û���ˡ���Ȼ����Ƶ�ʵ�����Сʱ����һСʱ��ʡǮ����������ص�ʵ������ʹ���ۿ��ˡ�����������ģʽ�ڸ�Ƶ�����������£����ۼҾӻ�����ҵ��������̫���㡣 ��һ����ʹ�ҿ��DZ��ط�������������˽����ͥ��صĻ���������ƶ˷�������±����ͷ�ֱ�����������ڶ�ģ̬�Ŀ�ԴСģ���Ѿ��㹻ǿ�ˣ��ҵ� OpenClaw �����Ͳ����� Mac mini �ϣ�16GB ͳһ�ڴ���һ��С�� G ���Ӿ�ģ����ȫûѹ�������ڿ�����������û���ˡ�è�ڸ�ɶ���ֲ�Ҫ���ݴ��ʵij���������Сģ�͵�������ȫ���ã�ȷʵû��Ҫ���������ƶˡ� 2.2 ���� Ollama + MiniCPM-V ��Ȼ�ɱ�����˽��ָ�ز��𣬽���������ѡģ���ˡ�Qwen3-VL-8B ����֮ǰ����ҵ�ʼ���Ŀ��ʱ���ù���Q4 �������� Mac ������������Ч�����С�������뻻һ�����ԡ�������ܵ� MiniCPM-V 25 �� 8 �·ݷ����������ڿ�Դ���������ۺܶ࣬�ų��Ƕ˲��Ӿ�ģ�͵�С���ڣ�8B �ߴ磬�� Ollama ��������ֻ�� 5.5GB�����Ҿ�˵����ҵ���߱���ˢ��Ƶ���������Ķ�ģ̬ģ�͡����ó������Ŀʵ��һ�¡� |
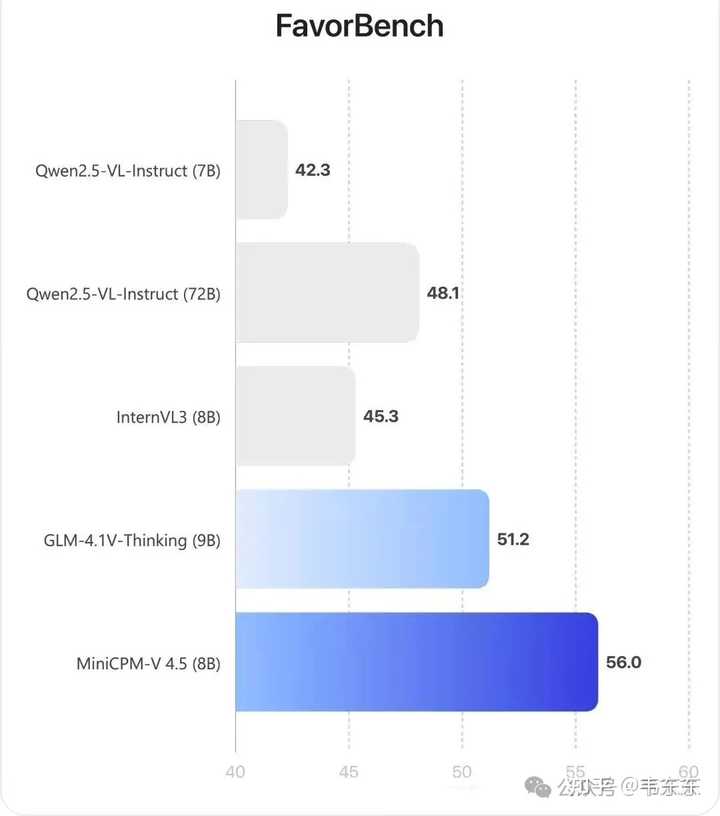
|
|
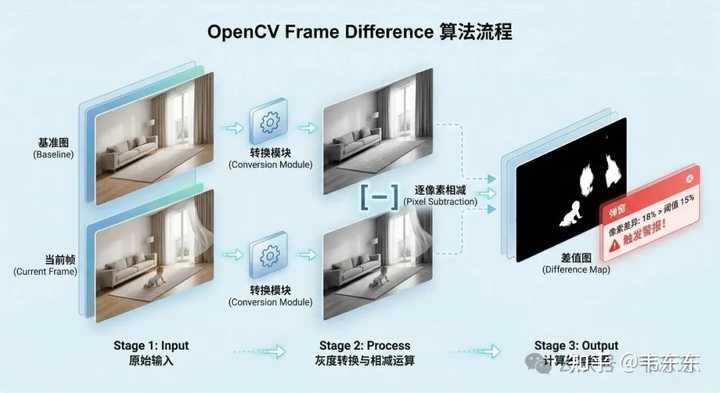
ʵ��ʱ���˼�����ʵ������ͷץ����Ƭ�����ǿ�������̨����������MiniCPM-V �ܺܺõ�ʶ�������ɢ�����ߡ����˱��ź������ೣ�����棬Ҳ���ж���̨����û��è�����صĽṹ�� JSON ��ʽ�ȶ�����������Ҳ�Ƚ���Ȼ�����ڿ�������������ʲô���������˵����ȫ���á� ��������Ҳ���幻�ã� ָ����ֵ���������״μ��ؽ��ڴ棩~21 ��/����������ģ�ͳ�פ�ڴ棩~5.5 ��/��ģ�����5.5GB�����豸Mac mini M4, 16GB ͳһ�ڴ� �� Apple Silicon ��ͳһ�ڴ�����������ȫû�п��١��������� Cron ����ÿ 2 ���Ӵ���һ�Σ��൱�ڳ����� Ollama ���ģ��һֱ��פ���ڴ��ﲻ�ᱻж�أ�Ollama Ĭ�� 5 ����û������ͻ��Զ�ж��ģ���ͷ��ڴ棬�´ε����ֱ������������ʵ�������ӳ��ȶ��� 5.5 �����ҡ� ˳����һ��ѡ��ʱ�ȹ��Ŀӡ��ڲ� MiniCPM-V ֮ǰ����Ϊ��ʡ�ڴ����Թ� Qwen3-VL �� 2B �汾���������ͼȫ�����ؿ��ַ�����JSON ����ֱ�ӱ���������һȦ GitHub Issues �� Reddit �ŷ����ⲻ�Ǹ�����Qwen3 ϵ���� Ollama ������ format: json ʱ��������ݻ�д���ڲ��� thinking �ֶε��� API ����Ϊ�գ�ͨ�� Ollama API �� base64 ͼƬʱҲ��ż���շ��أ����� 2B �����������Ը��� JSON Schema + ���� Prompt + ͼƬ������Լ����������·ȷʵ�����ױ�����Щ������С�ߴ�ģ���ڹ��̹����еIJ��ȶ��Ա��֣�ģ�ͱ��"֧���Ӿ�"����ʵ����Ŀ��������ͨ�������£�ѡ��һ��Ҫ����ʵ���������˵��˲��ԡ� 3 YOLO Ԥɸ�������ز������� ��ģ̬ģ��ѡ���ˣ�������һ����ǰ�õ�����û�����ÿ 2 ����ץһ��ͼ��ÿ�Ŷ�ֱ�Ӷ��� MiniCPM-V ��һ��Ļ���5.5 ��һ�ţ���ʱ�仭����ʲô��û�����������˷������������� MiniCPM-V ֮ǰ������Ҫ��һ��������ǰ���жϣ�Ҳ�����жϻ����ﵽ����û���˻�è���в�ֵ�û��� MiniCPM-V ����һ�������� 3.1 ���ز�ֵ������ֱ���ķ�����Ҳ�����ȱ��� �ʼ��˼·�ֱܼ���ֱ���� OpenCV �����ز�ֵ���ȼ���һ�����������ԭ�������ǰ�����ͼƬ��ת�ɻҶ�ͼ��ÿ������ֻʣһ�� 0-255 ������ֵ����Ȼ�����������������õ�һ�Ų�ֵͼ����ֵͼ�����ĵط���������ͼ��һ��������ͳ�������ص�ռ�Ⱦ��ܵõ�һ���仯�ʡ���һ�ſշ���Ļ���Ƭ��֮��ÿ��ץ�Ķ��ͻ��Աȣ����ر仯���� 15%�����Դ����ģ�����Ϊ���춯�����Ѷ�ģ̬ģ��ȥ��һ�������� |
|
|
���������·��֣����������ֱ�ӵ�������ǻ�����Ⱦ���ɿء����仰˵������Ļ���Ƭ��ʱ������ǡ�÷��˸����ֽ�䣬����Ӥ��������֮�����ֽ�䱻���ߡ�Ӥ���������ߺ�ǰ����ͻ��IJ����һֱ���ڡ�ϵͳ�ͻͣ���� MiniCPM-V ȥ��һ���շ��䡣 ��Ȼ����һ�ָ��õ�˼·�ǻ��ɶ�̬���ߣ�Ҳ���Dz����̶���ͼƬ�ȣ�����ÿ���õ�ǰ֡��T������һ֡��T-1���Աȡ��������ƺ���������ʵ�ʻ��Dz��У���Ҫ���������⣺ ������Ʈһ�¡����ӻ����л���ɨ�ػ������ܹ�ȥ�����Ǵ�������ر仯��ȫ�������澯; ©������������ڵص���˯���ˣ���������һ��������T �� T-1 �����ز�Ϊ�㡣ϵͳ�ж��ޱ仯��ֱ����������ʵ���������Ҳ��Ҫ��ע�� ˵���ˣ������ؼ��ıȶԸ��������⻭�����ݣ��ֲ��崰����Ʈ���и��˽����ˡ�Ҫ���������⣬���ǵô����ع���������������ˡ� 3.2 ���� YOLO��0.03 ���ж���û���� YOLO��You Only Look Once����Ŀ��������ı��ģ�ͣ�������һ��ǰ��������ͬʱ���Ŀ�궨λ�ͷ��ࡣ�������ر��˶��٣�ֱ���жϻ�������û�� person����û�� cat�� ���ܲ����������Ѷ�ֻ�� YOLO ��ɶ��������������һ�¡�YOLO �ڹ�ҵ�Ӿ�����Ӧ�÷dz��㷺�����繤�������ϵ�ȱ�ݼ�⡢��ͨ�����ij���ʶ�𡢰��������Σ����Ʒ���ȡ�����Щ����ͨ����Ҫ����ض�Ŀ����������ͼƬ��ע��ģ��ѵ�����ż����͡� ��������Ҿӳ����Ƚϴ��ɣ�YOLO �ٷ���Ԥѵ��ģ���ǻ��� COCO ���ݼ���Common Objects in Context���������Ĵ��ģĿ��������ݼ���ѵ���ģ����伴�þ���ʶ�� 80 ��������𣬰��� person��cat��dog��car��bicycle��chair��couch��tv��cell phone��backpack �ȵ��ճ����塣����Ҫʶ����˺�èǡ�þ����� 80 �����棬��ȫ����Ҫ�����ע���ݣ�����ֱ���þ��С� ���ԣ����� YOLO ֮��Ԥɸ���ӡ�����ͼ������ͼ��ʲô��ͬ������ˡ�����ͼ����û�й��ĵĶ�������һ�������Ե������� ���и����⻰����ʵ YOLO ϵ�о�����������Ѿ��зdz���汾�ͷ�֧�ˣ�������� YOLOv1 ���������µ� YOLO26��2026 ����� Ultralytics ������ר����Ա�Ե�豸�Ż������м仹�� YOLO11��YOLO12 �ȡ����ﲻ����չ������ͬ�汾���죬��ֱ��ѡ��ҵ���õ����Ҳ������ YOLOv8 ϵ�С�YOLOv8 �ṩ�˴�С����Ķ��ֳߴ磬����� 6MB �� 130MB ���ȡ���Ϊ�DZ����ܣ����Բ��Ծ��Ǵ���С�Ŀ�ʼ�����ԣ��ҵ�Ч���������ƽ��㡣 һ��ʼΪ�������ٶȣ���������С�� YOLOv8n��Nano �棬6MB�������ʵ�ⱦ�����Ű�ɫ���������ڵ����ϵ�ʱ��Nano ģ�Ͱ���ʶ����� teddy bear��̩���ܣ������Ŷ�ֻ�� 0.28������Сģ��ѹ��̫�ݵ��µķ���Ư�ƣ���̬������һ����ϴ��� |
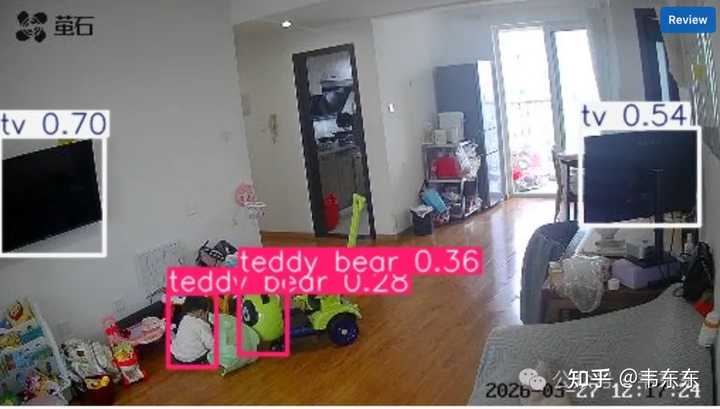
|
|
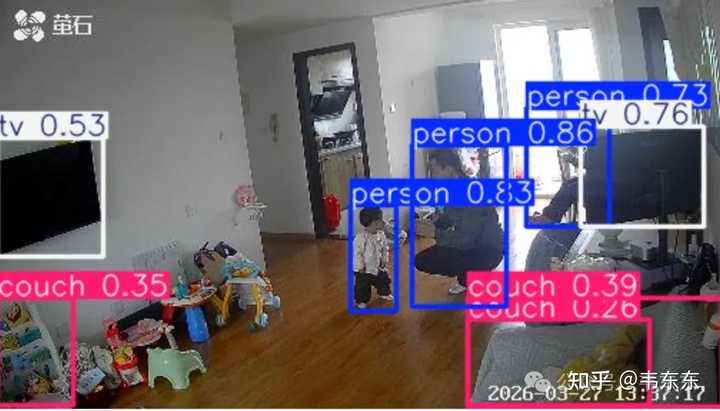
YOLOv8nʶ��Ч�� ����������һ��ȫϵѹ�⣬�� Mac mini ����ͬһ�ſ������ӻ��棨���������˶��ڣ�����һ�飺 ģ�����������ʱ������Ŷ�©��YOLOv8n (Nano)6MB~12ms0.28����ʶ����YOLOv8s (Small)21MB~36ms0.86��YOLOv8m (Medium)50MB~74ms0.89��YOLOv8l (Large)83MB~130ms0.90�� |
|
|
YOLOv8sʶ��Ч�� �� Small �� Large������ʱ�䷭�˽� 4 ���������Ŷȴ� 0.86 �� 0.90 ��������ʵ��ϵͳ��������塣ֻҪ���� 0.4 ����ֵ�ű��������ߣ����� 0.86 �� 0.90 û���κμ�ֵ������ѡ�� YOLOv8s��36 ������һ�Σ���������գһ���۾����죬������ 4 ·���Ҳ����ѹ���� 3.3 ��Сģ�ͼ�����YOLO Ԥɸ + VLM ���� �ܽ���˵��YOLO ���Ƚ���ˡ���û�С������⣬����û������������������û������д Prompt����ֻ�ܸ����㡰�������и� person�������ֲ������ person �DZ�������������ɨ�ء��������յļܹ������㼶���� ��һ�㣺YOLO ����Ԥɸ���ɱ����ͣ��� ��������ͷ�Ĵ���ֻ�� person ��ǩ������è��ɨ�ػ�����һ�ɺ��ԣ���̨����ͷֻ�� cat �� dog����һ�� 36 ���������ɣ����˵� 90% ���ϵĿջ��档 �ڶ��㣺MiniCPM-V ��ϸ�жϣ��ɱ��ϸߵ������� ֻ��ͨ�� YOLO Ԥɸ��ͼƬ�Ż��͵� MiniCPM-V����ģ�������⸴��ָ�����"�������DZ����ڶ�����ˣ�������д������Ա߿���"����� MiniCPM-V �ж�"��ֻ��������ɨ��"��������·��Ĭ�������������κ���Ϣ�� �������ܹ��ĺ���˼���ǣ��ü�����ɱ���Сģ���˵����������Ч����ֻ��������Ҫ����Ļ��潻����ģ�͡� ��ʵ�������У�YOLO ÿ����˵���Լ 90% ��ץ�ģ���ģ�͵�ʵ�ʵ��ô�����ÿ�� 720 �ν����� 60-70 �Σ�Mac mini �ĸ���Ҳ�ӳ�����λ����˼�Ъ�Եĵ��ɡ� 4 ץ�ļ�¼�������Ҫ������������� ����Ĵ�Сģ�ͼ����ܹ��������Ѿ���ͨ�ˣ�YOLO Ԥɸ �� MiniCPM-V �ж� �� ���ͷ���Ⱥ�������ߺ�ܿ췢��һ����������⡣YOLO ���������˻�è��MiniCPM-V Ҳȷ���ˣ�����������Ⱥ��� 10 ��¼�� GIF ��˺�èҪôֻʣ����Ӱ��Ҫô�Ѿ���ȫ�߳��˻��档 |
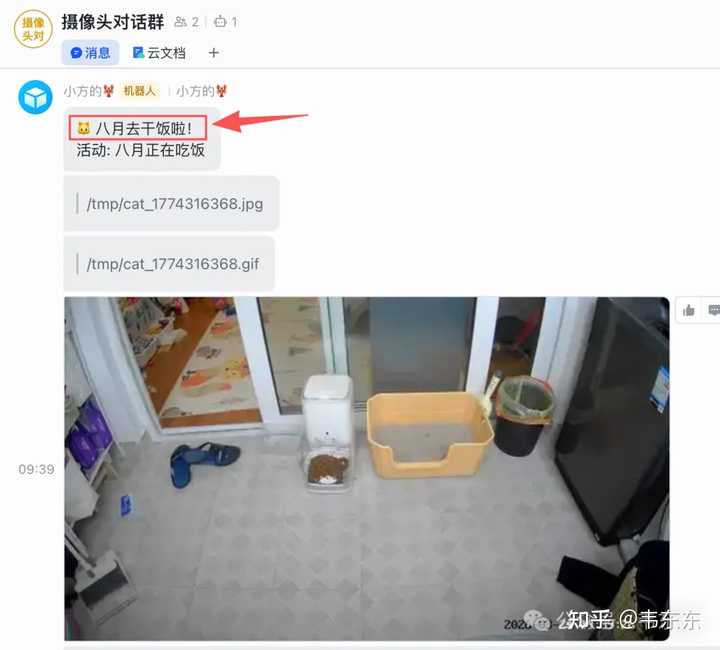
|
|
4.1 ��˵Ϊʲô�� GIF ��������Ƶ �����һ�䣬Ϊʲô����ѡ�� GIF ��������Ƶ���ʼ��ȷʵ���� ffmpeg ¼ 10 �� MP4��Ȼ�����ļ����ӵ���ʽ��������Ⱥ������鲻�ϱ��� file:// Э�顣�����ڹ�˾�õ��Դ��飬������ Mac mini �ϵı���·�������ҷ�������˵� API ��ֱ�ӷ�����Ƶ�ļ����ϸ�Ĵ�С��ʽ���ơ� �������˸�˼·������ֱ���� ffmpeg �� 10 ����Ƶѹ�ɶ�̬ GIF��-vf fps=5,scale=480:-1 -c:v gif��������ԭ��֧�� GIF ������ʾ�������촰�����Զ�ѭ�����ţ����õ�����������أ�����ȷ���Ƶ�ļ���̫���ˡ� 4.2 ʱ�����Ų飺T+8 �����ˮ���ӳ� �ص����⣬GIF ������ˣ���һ��Ӧ��¼��ʱ��̫�̻�������ͷ�Ƕ������⡣���������֮��������ͷ�Ƕ�û���⣬�������ʱ�����ϡ� Ϊ�˷������⣬�Ұ�������ˮ�߰�ʱ����һ���λ������ˣ� �� 0 �룺Cron ��ʱ��������өʯ�� API ץ��һ�ž�ֹ��Ƭ���˿̱��������ڿ������롣 �� 0.5 �룺YOLO ����Ԥɸ��36ms�����ж��������� person�� �� 1~6 �룺ͼƬ�� MiniCPM-V����ģ�ͻ� 5.5 �������������� �� 7 �룺MiniCPM-V ���ؽ����ȷ���DZ������ű���ſ�ʼ���� ffmpeg ��ֱ����¼�� �� 8~9 �룺ffmpeg ��өʯ�� API ��ֱ������ַ��~1 �룩���ٽ��� RTSP/HLS �������֣�~1-2 �룩�� �� 10 �룺ffmpeg ������ʼ¼�ƻ��档 Ҳ����˵����ץ����һ�̵� ffmpeg ������ʼ¼���棬�Ѿ���ȥ�˽��� 10 �롣С���� 10 ���Ӳ�֪����������ȥ�ˡ����� GIF ������˻���è����ȫ�����ģ�¼�����·� 10 ���Ļ��档 4.3 ��һ�θĽ���YOLO �ж����˾Ϳ�ʼ¼ ��������֮��һ���뷨�Dz�Ҫ�ȴ�ģ�ͳ�������¼�����ǰ�¼�ƶ���ǰ�õ� YOLO Ԥɸ֮��YOLO ֻҪ 36 ��������ж���û���ˣ��ж����˾������ں�̨���� ffmpeg ��ʼ¼��ͬʱ��ģ�Ͳ����������������ģ������ж���������ֻ��������ɨ�أ���������ɱ�� ffmpeg ���̡�ɾ����ʱ GIF�������͡� �����Ͼ����� subprocess.Popen ���������� ffmpeg����ģ�ͺ�¼�Ʋ���ִ�С� ������һ�⣬GIF ��Ļ��滹�����ӳ١��Ų鷢�֣���Ȼ���� YOLO �������Լ�� 0.5 �룩�ͷ�����¼������� ffmpeg �ڲ���Ҫ��һ�顰��ȡֱ������ַ + �����������֡������̣���������ֳԵ��� 2-3 �롣ʵ�ʿ�ʼ¼�ƻ����ʱ���� T+3 ������������������è�����п����Ѿ��߳������ˡ� 4.4 �ռ�������ץ�ĵ�ͬʱ�Ϳ�ʼ¼ ������֮����ʵ�ܼ���Ӧ�����κ��ж�֮�������¼�ƣ���Ӧ����ץ����Ƭ����һ˲���ͬ������ ffmpeg ������ �µ�ʱ�������ˣ� �� 0 �룺Cron ������ץ�ľ�ֹ��Ƭ �� ͬʱ��̨ ffmpeg ��ʼ�� API ��ֱ������ַ���������� �� 0.5 �룺YOLO Ԥɸ��ɣ�36ms���� 1~2 �룺ffmpeg ������֣���ʼ����¼�ƻ��档��ʱ����ղ�ץ�ĵ���Ƭ�߶�һ�� �� 1~6 �룺MiniCPM-V �ڲ��������� �� 7 �룺��ģ�ͳ����ۡ���ʱ GIF �Ѿ�¼�� 5~6 ��Ĺؼ����� ��� YOLO Ԥɸ�ж�������û�й��ĵ�Ŀ�꣨�շ��䣩�������� terminate() ɱ����̨ ffmpeg ���̲�ɾ����ʱ�ļ���Ͷ���ɱ�����һ�� API ���úͼ���� ffmpeg ����ռ�ã��������Ժ��Բ��ơ� ��������ĺ���˼���ǣ����������۵� + ����ʱɱ������Ͷ��ʽԤ¼�ƣ��ȡ�ȷ�Ϻ���¼���ı��ز��Ժõöࡣ �����Ͼ����ü������� CPU ������ɱ�����ȡ�˻����ʱЧ�ԡ�����֪ͨ��·����ѹ������Լ 8 �루5.5 �� AI ���� + 2.5 �����Ͷ�ݣ���GIF �������ܿ����������˺�è�ˡ� 5 Skill ��װ�����Ⱥ���� ������·ȫ����֮ͨ�����һ���ǰ���Щ��ɢ�Ľű�������ͳһ��װ���������� OpenClaw�������������һ���ճ����õĹ��ߡ� 5.1 �Ӳ��Խű��� monitor.py �ع������������̣�ǰ�漸�½���ÿ�����ڣ�өʯ�� API �Խӡ�Ԥ�õ���ԡ�YOLO Ԥɸ��MiniCPM-V ������ffmpeg ץ�ļ�¼���ڿ�������ʵ���Ƕ����IJ��Խű���API ������ api_test.py��Ԥ�õ��� preset_wizard.py��YOLO ѹ���� yolo_bench.py�����ܸ��ġ� �����Ұ�����������£����һ�� 600 ���е� monitor.py �ļ������װ�������˵��˿��������л��۵�ʮ�������Խű��ĺ�������������ϵͳ�����棺����ָ�� �� ��������ͷ �� ץ�� �� YOLO Ԥɸ �� VLM ���� �� ���� GIF �� ��������һ���ű����ȫ��·�� �� OpenClaw �� Skill ��ϵ�һ�� Skill �����Ͼ���һ�� SKILL.md��������� Skill ����ʲô����ô���ã�����ʵ�ʵĽű��ļ���Agent ͨ�� SKILL.md ������������"�û�˵����仰��Ӧ�õ����ĸ�����"���������ڷ���Ⱥ��˵"���ҿ�����������ʲô���"��Agent ��֪���õ� monitor.py �Ŀ���Ѳ����� ����Ҫ����һ�㣬������һ�����������ļ�ֵ���������ڷ���Ⱥ���ֶ�����ָ��ȥ������ͷ���ǻ�����ֱ�Ӵ�өʯ�� APP ��ʵʱ�������ÿ졣������������ǽ�����Ҫ���Ķ�ʱ����ϵͳ�ں�̨�Զ�Ѳ�ӡ��Զ��жϡ��Զ����ͣ��˲���Ҫ���κβ�������������������������㡣 5.2 ������ͷ·�ɣ�һ����ֱ���Ŀ� �����и��ȿ�ֵ�ý���������������ͷְ��ͬ�������Ŀ���������̨�Ŀ�è����һ��ʼ SKILL.md ������д��̫��ͳ������ Agent ����������������ʡ����½�����˼��η�����������è�����֣���Agent ȴȥ���������ͷ��Ȼ��ظ�"������û�п���è"�� |

|
|
�ⷨ�ܱ�������Ч���� SKILL.md ���ü���ǿ�ҵ�������·�ɰ���������ͷ������д����"ר�ſ�������ǧ�������������ͷȥ��è"����̨����ͷд����"ר�ſ�è"��Agent ������ǿ��������ָ����Ӷȷdz��ߣ�����֮����Ҳû·�ɴ����� 5.3 ��ʱ����ʵ���Զ��� ��װ�� Skill ֮��ͨ�� OpenClaw �Դ��� Cron ��ʱ������ʵ���Զ������У� ����Ѳ�ӣ�ÿ 2 ���ӣ�����������ͷ�Զ�ץ�� �� YOLO Ԥɸ �� ���˲Ż��� VLM �� ȷ���DZ��������� GIF è��Ѳ�ӣ�ÿ 2 ���ӣ�����̨����ͷͬ������è������ ��ͥ�ձ���ÿ�� 18:00��������һ���Ѳ�Ӽ�¼������һ�ݺϲ����ձ����͵�Ⱥ�� �⼸�����������Ҳ�dz����IJ��ԣ���ש������Ѳ����Ҫ���Һ����Ų��ڼҵ�ʱ����֪�����ڿ�����ʲô������״̬��ô����ϵͳ�������ͻ�����һ�� GIF ����Ⱥ�û�µ�ʱ��㿪��һ�۾��У�����ר��ȥ����ػطš�è��Ѳ����Ҫ�ǿ���ÿ��Է�����ˮ���ϲ������������̨����ͷ���ø�����è��ʳ���èɰ�衣 |
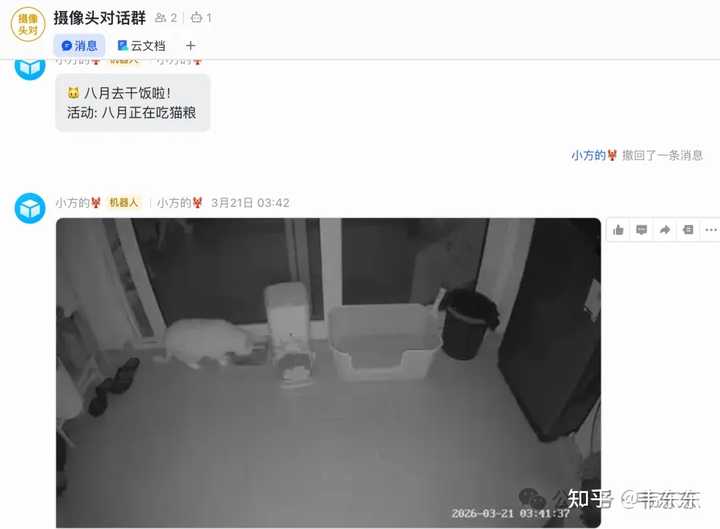
|
|
��ÿ�� 18:00 �ļ�ͥ�ձ��൱��һ��������ܣ����챦���ڿ��������˼��Ρ���������ʲô��è������˼��١���Ծ����ô���������ܽ���һ���ձ����ƹ�������������ÿ��ؼҷ���Ƶ��¼��ɨһ���ձ��Ͷ�һ�������и������˽⡣ |
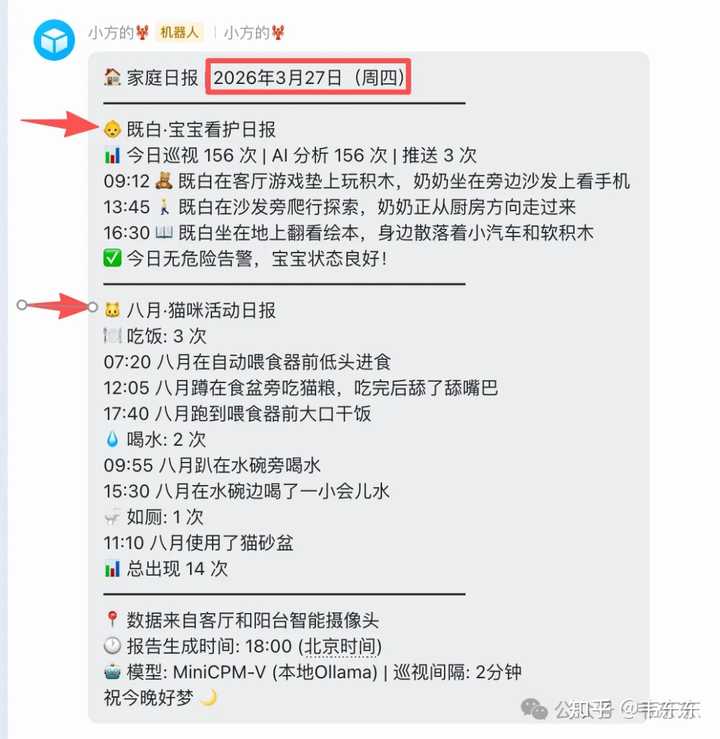
|
|
5.4 ��ĬЭ������Ϳ��� ����һ��ϸ�������ǣ�Ѳ�������ʱ�仭����ʲô��û�У��ű�����Ҫ����κ����ݡ�������ű�ʲô���������Agent �������Բ�һ��"һ�а�ȫ~"����Ⱥ�һ�켸����һ�а�ȫ�������粻���� �ⷨ���ڽű��ﶨ����һ�� [SILENT_SAFE_STATE] Э�顪�����·���ʱ�����������ǣ��� Cron �� message ��ǿ��Ҫ�� Agent ���������Ǿͱ��죬��Ҫ���κλظ������� 99% ��ʱ��Ⱥ������ȫ��Ĭ�ģ�ֻ��������Ŀ��Ż�����һ�� GIF����Ȼ��ǰ��Ҫѡ������õ�ģ�ͣ�ָ����ѭ�ſ��ס� �������������ȴ��ͬһ���¼������籦���ڿ�����1 Сʱ��ֻ����һ�Σ����ⱦ���ڿ�����һ���磬Ⱥ��ÿ 2 ������һ���ĺ�ը����˽����Ҳ�����������ƣ��ڷ���Ⱥ��˵�������ˡ����ű����өʯ�� API ������ͷ��̨ת���컨�壬��������ȷ�����ĵ��κλ��棻���� 6 �㵽���� 6 ����˶��ڼң��ű���� _is_quiet_hour() ���Զ���������Ѳ�����Ȳ��˷�������Ҳ�����ҹͻȻ�Ƹ���Ϣ������ 5.5 �ճ����� ����ϵͳ�ȶ�������֮���ճ��������������ģ� ����ʱ��Ⱥ������ȫ��Ĭ�ġ������������ˣ���һ�� 10 �� GIF��Ȼ���Ĭ 1 Сʱ��èȥ��̨�ɷ��ˣ�ͬ����һ�� GIF��Ȼ���Ĭ��ÿ�� 18:00 һ�ݺϲ���ļ�ͥ�ձ���������Ѳ�Ӽ�¼��è�ijԺ�������ϸ�������档��Ȼ����������ʱ��Ⱥ��������ѯ��ʵʱ������ͷ��һ�Ż��������� �����������гɱ����Բ��ƣ�API ���� ��0������ Ollama����Ӳ��ȫ�Ǽ������еģ�Mac mini + ��̨өʯ������ͷ�����¶ȳɱ����Ҫ�����һ���ѡ� 6 д����� 6.1 �ӿ���������������˼·��Ǩ�Ƶ����� ��ͷ��������Ŀ����������ʵû���õ�ʲôǰ�صĶ�����өʯ�ƵĿ��� API��һ�� 8B �Ŀ�Դ�Ӿ�ģ�͡�һ�� 21MB �� YOLO Ŀ����ģ�͡�ffmpeg ¼�� GIF�������м�ֵ�IJ���ij�����㼼������������"����ͷ + Сģ��Ԥɸ + ��ģ�;��� + ��ʱ���� + ��Ϣ����"�����ģʽ�� ���ģʽ�ı����ǣ���"�˶���Ļ"���"AI ����Ļ���˶�֪ͨ"���κ�һ��������ֻҪ����"�Ѿ�������ͷ"��"��Ҫ����һֱ����"���������������ܹ�����ֱ��Ǩ�ƹ�ȥ�� �ٸ���֮ǰ��һ�����������������İ�����һ�ҽ��������꣬��ҵ���жϽ�����û��ı��ܼ����Ӹ���ˮ�������Ϳ������ˡ��½��ӵ�Ա����Ȼ�ᶢ�Ź������ϰ嵣�ĵ�����һ���¡�æ��ʱ��Ա��Ϊ�˸ϵ���û�Ƚ���ȫ����������ǰ���ˣ������Ľ��Ӷ������������Ͷ��ˡ����˶��˲���ʵ���ϰ岻����վ��ÿ�ڹ����濴�� �������������ڹ��Ϸ�����һ������ͷ������һ���˲��Ӿ�ģ�͡������湤�����Ҿ����˽����£���Щ���������Ϸ�ȫ��ˮ���������ݣ�����ͷ����Ҫ�������£�ͼ��Ԥ����Ҫ���˲�����ȥ�����ݲ�������ٱ�Ե��Ŀ�����õ�������ģ�ͣ�YOLO �� MobileNet ���𣩣�ѵ���α�ע������ˮ�е�����״̬�������ס��븡����ȫƯ�������Ҳ���ֻ����֡�����ý��"����Ư��ʱ��"���ж��Ƿ��������죬���ⷭ��ʱ�����С������ϰ���˵��ģ�����ջش�ľ���һ�����⣺���������ȫ��������û�У����������˾Ϳ�ʼ��ʱ�����˱�ʱ�������Ա���̡� |

|
|
��������Ϳ�����Ŀ���ں���ȫһ�£��Ѹ������⽵ά��"��/��"�жϣ�����С��ģ������ȷ�����£���̨�ù��ף����ͨ����Ϣͨ����ͨ���һ������������ Agent + ��ʱ����Ŀ�ܣ��ϰ�Ϳ����ڶ���Ⱥ����"���켸�����ӳ�ʱ��"��ÿ���Զ��յ�����Ч���ձ�����껹��ͳһ�㱨���������� ���Ƶij������кܶ࣬���ſڵķÿ�/������ѡ�������ռ�ü�⡢���ۻ���ȱ��Ѳ�졢������ȫñ������顢Σ���������ָ澯�����ײ�������һ���ġ� 6.2 ���������Ŀ�ļ��乤�̷����� �����Ŀ��Ȼ�Ǵӿ���è�����ģ�����������������һ�������жϣ���ģ��ƾ�跺�����������������������˴���֮ǰ����·�������˵�Ӧ�ó�����������ʵ����� AI ������ֻ��ƴͼ�е�һ�飬������һ��������Ҫ����һ�顣 ����������ϵͳ��˵�������õ���ģ�͵Ļ���ֻ�г������⣬�е����Ƶ���������� 15 ����е� YOLO������һ�е��� ffmpeg��Cron������������Щ�ϹŶ�����ģ�͵ļ�ֵ����ȡ����Щ���������Ǻ�����Эͬ�� ���������������Ŀ��ͬ������������֮ǰ���ܹ�����ǰ������Ŀ����������õ��˾����㷨�����ƶȹ��飬�ṹ�����ݵı��ſ����ǹ�������;��� NLP����ģ��ֻ�����һ������Ȼ�������ɺ����������ס�������ĵ�һ�����ܼ�����ĿҲ�����ƵĽṹ�����ĵ��ܺļ�����쳣����Ǵ�ͳ�㷨��������ģ������DZ������ɺ��˻������������ܽ�����ϵͳ�������Ǵ�ģ�͡���ͳģ�ͺ;����㷨��˾��ְ�Ľ���� ���Թ���������Ǿ��ϻ���������ͳ���Ϊ����ѡ��������Ҫ���Ŵ����Ҷ��ӡ� ���ּܹ���ÿһ��ְ���������������κε�һ����·�ߡ����� 21MB �� YOLO ����ľͲ�Ҫ���� 5.5GB ���Ӿ���ģ�ͣ����� Cron ��ס�����Ͳ�Ҫ���� Agent ȥ������ 6.3 Դ����γ� �����Ŀ������Դ�����Ѿ���װ���� OpenClaw Skill ѹ������������ SKILL.md��Skill ���壩��monitor.py��600 ���еĺ��Ľű�����.env.example����Կģ�壩�Լ�����ͼ�Ľ̡̳���������Ҳ��өʯ������ͷ��һ̨ Mac mini�������Կ��ѹ�� Skills Ŀ¼�£�10 ���Ӿ�����������������Ʒ������ͷ�Ļ���һ�� API ��������䡣 |
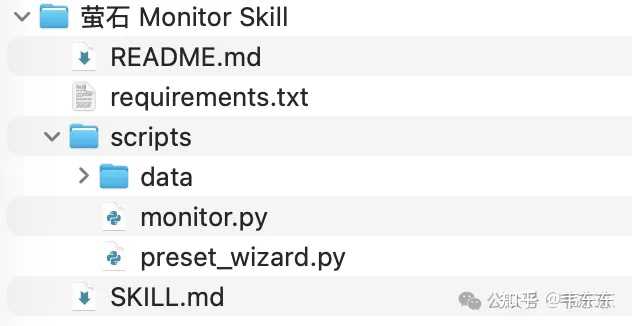
|
|
���� Skill ��Դ��������̳��Ѿ��������ҵ���ҵ��ģ��Ӧ�ô����ŵ�������Ƶ�γ̺�֪ʶ������γ�֮���� 15 ��������ҵ����ģ��Ӧ����ذ������֮�⣬��������������ڸ���Щ����һЩ���߰���Ϊ������Դ��֪ʶ������ԱȽ��ʺ���һ�߲�����Ŀʵ�������ѣ��л�Ա����Ⱥ���ṩ�ճ���Ѵ��ɣ����������������Ƶ�γ̡� |
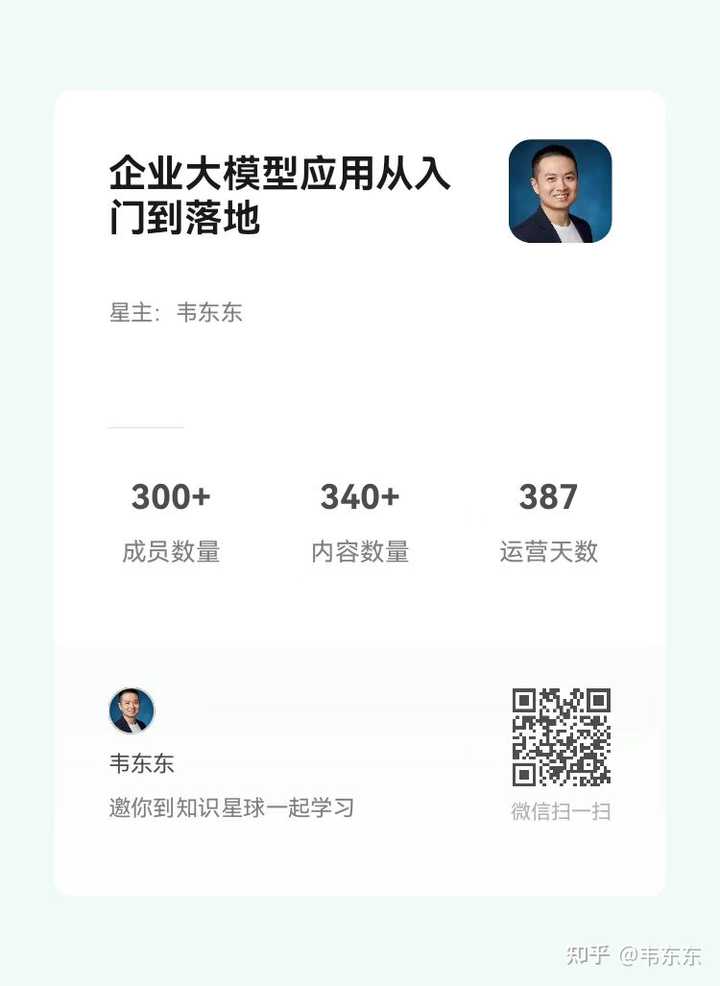
|
|
�γ����ӣ� ������ӣ� ����Ԥ�棺��ƪ���£��һ���ǰ Tesla AI �ܼ� Andrew Karpathy �� Autoresearch ��Դ��Ŀ˼·����ʾ���ʹ�� Claude Code���ڼ�ǧ�Ÿ���ȱ�����ݼ���ȫ�Զ���ͨ YOLO �㷨��ʵ��������������Ѱ�Ų��������˸��Լ۱ȵij��������ţ�����̽������ô�ģ�������Ԥ YOLO �ĹǸ�����ṹ������������ȫ�µ�ע����������ͻ�Ƽ�⾫�ȵ��컨�塣ϣ�����Դ���ש����λ̽�ָ��� AI Agent ����ʵ��ҵ�����µ�Ӳ�˽ⷨ����ӭ��һ�ס���RAG���֮�����ӹ���������ҵ��Agent��(Τ����)��ժҪ ���� �Զ���- ����ͼ������Ԥ�棺��ƪ���£��һ���ǰ Tesla AI �ܼ� Andrew Karpathy �� Autoresearch ��Դ��Ŀ˼·����ʾ���ʹ�� Claude Code���ڼ�ǧ�Ÿ���ȱ�����ݼ���ȫ�Զ���ͨ YOLO �㷨��ʵ��������������Ѱ�Ų��������˸��Լ۱ȵij��������ţ�����̽������ô�ģ�������Ԥ YOLO �ĹǸ�����ṹ������������ȫ�µ�ע����������ͻ�Ƽ�⾫�ȵ��컨�塣ϣ�����Դ���ש����λ̽�ָ��� AI Agent ����ʵ��ҵ�����µ�Ӳ�˽ⷨ����ӭ��һ�ס� |

|
|
btw ��ӭѡ���ҵ��飬ȫ�������� |
|
������openclaw 360��Сʱ֮�ŷ����������ֱ����һ����ͨ�˸�Ǯ��Ч��Ұ·�Ӱ������������ܽ��3����ʵ�õ�openclaw�����淨�� ��ǰ������AI������һ��һ��ʽ�� ��Openclaw��һ������������˼�����⡢������Ϣ������ֱ�Ӳ�����������ִ�������ܰ����й��̺����϶������¼���鵵����ʱ���á� �㲻ֻ�Ƕ���һ����������ˣ����Ƕ���һ����˼�����ܸɻ���ܼ�סһ�е����������Ŷӡ�ֻҪ�����ܲ�������������ܽ���������Ҳ����Ҫ�ټලAI��һ������ɣ�openclaw����24Сʱֱ�Ӱ���ӹ�AI !�ⲻ���ĺ�����顣 |
|
|
���ܶ��˿���������ʵ���Ῠ��ͬһ�����⣺ OpenClaw������ô��0�����Զ���������ô������������ ��Ϊ���������û�˴��Ŵ�Լ�������ʵ�ر��ʱ�䡣 ��֮ǰҲ���о��˺ܾö�û��ͨ�����������п���һ��ҵ�ڴ����������AI��� OpenClaw ʵս�����Σ�������������������˳�� ���������������ݣ�day1��0��1�ְ��ֽ��㻷������AI�Զ����������Ĵ�������2026����ֵ�ø�ı�����ҵ��������day2ֱ�ӽ���Ӵ������ϵ�����̵���Ŀ������������������ܸ㵽Ǯ���� ���Լ����Ŵ��˼�����Ŀ����������Ҿͽ��˼����Զ�����С���ӣ�ǰ���� 5k+��������~ �����Ҳ�뿴�� openclaw�������Զ�����ʲô�̶ȣ���ͨ����ô�����ܳ����������ߣ����Ե�������������ڿ�������������openclaw��װ����̳̣�����������ѵģ�������������ʦ��ȫ���Զ�����Ŀ�ʼ�Դ������Ŷ ������ ��??openclawֱ����???AI������+AI��ҵ+ʵ�ٴ��� ��0.00������ȡ |

|

|
|
|

|
|

|

|

|

|
|

|

|

|
|
" style="display: none;"> �����£��������ӻ�ûʧЧ���ǵþ�����ȫ��openclaw�������������Ϲ��������С�openclawʵ����Ŀ����������openclaw�����ŵ���ͨ�������С���ҵ��Ŀ�ӵ����������Ӳ�������ҵ���ֶ�����������������ؼ��������ѵģ�����ʦ�Ǵ������ģ�ǿ�Ұ������Ͻ���ķ�ڣ� |
|
|
|
|
|
���Խ�����ƪ���ҾͰ��Լ��о������� 3����ͨ����ʵ�á���������ص�Openclaw����Ǯ������ƪȫ�����㽲����������� ���� + �ղأ���Ȼ���������ҿ��ܾͷ������ˡ� 01 Openclaw + GPT/DeepSeek �Ǿ����Զ����ɿ�����⣬����淨��ʵ�ܶ��˲�֪����������dz��� ҽԺ����ѵ������ҽѧ��������ԡ�ְ�ƿ��ԡ���ȫ������Ҫ��⡣ ����ͳ�����ķ�ʽ��ʲô����ʦһ��һ������������ۡ� ������ Openclaw + GPT / DeepSeek���������̿����Զ��ܣ�������ؼ����ǣ�����Ҫ����һ��һ��ʽ����AI��������Ҫ���ֶ������ݸ��Ƶ��ĵ��У���ֱ���Ľ��˫�֡� ���������������վ������400���ҽԺ��⣬ֱ���ۼ�19.9r������������284�Σ������ֻ��һƪ�ĵ�����վ�ϻ�Ū����ǧ+���ĵ��������治���롣 |
|
|
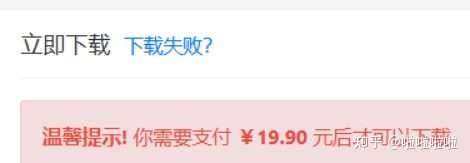
��Ҫ�������������ʵҲ����. ��һ���������������� �������� AI ������Ŀ�ṹ���������һ����ʾ�ʣ������ڿƳ����������ٴ���ϡ����Ʒ�����ҩ��֪ʶ������������ Ȼ���� AI ������ṹ������Ŀ�����磬��ѡ�⡢��ѡ�⡢�ж��⡢���������� AIһ�ξ������ɼ�ʮ���� �ڶ�����Openclaw�Զ�������400���� Openclaw��ǿ�ĵط����ǣ��Զ�ѭ��ִ������ ��ֻ��Ҫ���������� GPT / DeepSeek������n+���⣬���棬�ټ������ɣ�ѭ��400/n�Σ�400�������Զ������ˡ� ���һ����Զ�������ʽ�����ֱ�ӵ���Excel��Word������PDF��ʽ��ȫ���Զ���ɡ� ���Ϳ���ֱ�ӱ����������������ʵ�ܺ����� �г�����ܶ࣬һ���ۼ�19.9������ ��������һ�����ֻ��Ҫ��10�����ӣ��� |
|
|
��ؼ��ǿ���24Сʱ��������ɣ�����Ҫ�����Զ��֣�ֻ��Ҫ���ǰ�ڵ�����á� ����淨��ʵ���ǣ�AI��������֪ʶ��Ʒ���ܶ��������Ŷ���ʵ������ô���ˡ� ��ʵ�����Ҹո��ᵽ����Щ����֮�⣬���� 100 +���ر��ʺ��������ŵ�ϸ������������˵������Ʒ�Զ����ϼܹ�������������ױ��ҵ��������ͼ�ȵȡ�ֻҪ�������������˳�ˣ������Ͼ��Ѿ��߱���ʼ���ֵ������ˡ� �����Լ�Ҳ��һ�������Ž̳�����ѧ�겻��3���£���������Ŀд������еת�гɹ���ְ30k��AI��̵Ĺ�����dzdz����һ�ºٺ�~ |
|
|
�����Ҳ������� AI�Զ���������ô��ء���ô��0����Լ�����������Ŀ�����Ը���������AIӦ�ð�������ʵ��Ŷ�����϶��Ǵ������õģ�����ʵʱ���£���ȫû���κ���·�����ֱ����ȥ�þ���~~ �������ҷ��������ˣ�����Ȥ�Ŀ����Լ�ȥ��һ�� ������ ��??openclawֱ����???AI������+AI��ҵ+ʵ�ٴ��� ��0.00������ȡ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
" style="display: none;"> ��������һ�£�������ʦ֮�������ȥ�츣������ȫ����ҵ������������openclaw�����쵽�ж���Ƥ�顿���Լ����С�openclaw�����̡̳��ȵȣ���Щ�������ߣ����������£������Ǵ������ܸܵΣ�����ǿ�ҽ������ְ���һ�ݣ��� |
|
|
˵ʵ���������ʦ����ͦ���ĵġ��ܶ����϶��Ѿ������������ˣ��㲻���ٵ��������ϣ�Ҳ�����Լ���ƴ���գ�ֱ�Ӱ��ո�����·��ȥ�����̾����ˡ� 02 ��ý����Ӫʦ������ͼ �ڶ�����������ķdz��Ƽ�������������ý��ӵ����ˡ���Ϊ���ںܶ��˺�����������ǣ�Ч��̫���ˣ� ÿ��Ҫ��ѡ�⡢���⡢���桢�Ű桢�İ��Լ����������ȫ���ֶ�����û��1�����Ӷ��㲻����Ч����ĺ����� ���� Openclaw + AI �������������Զ����� |
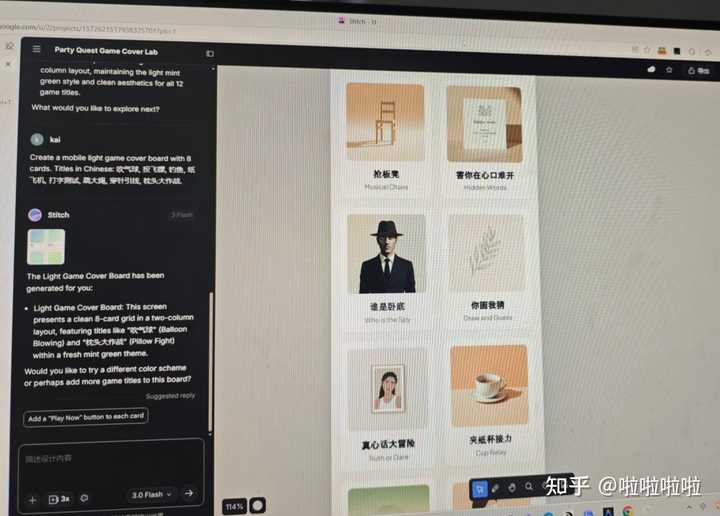
|
|
1���Զ�ѡ�� ���� GPTץȡ�ȵ㣬��С�������Ż��⡢�������Źؼ��ʡ�֪���Ȱ���Щ���ǿ��Եġ� Openclaw�����Զ�ץȡ���ݣ�Ȼ�� GPT / DeepSeek������20������ѡ�⡣ ���磬�Dz��Ǿͺ���С������ζ��~ ����ͨ��ǧ�������3���¡� ����Ȱ��һ��Ҫ֪����5�����ܡ� ��90%���˶���֪��������ɡ� 2���Զ�����������ͼ ����ط�����ý���Ŷ���ϲ���ġ� Openclaw�����Զ����ã�Midjourney��SD�����Ρ�Canva��Щ�����ͼ������ Ȼ������100�ŷ��棬��ȫ����Ҫ�˹������� 3���Զ��Ű淢�� �����Զ�ֱ�Ӱ��İ������ɣ�С�����ʽ�����ںŸ�ʽ��֪����ʽ��Ȼ��һ�����������������Զ��ӣ�emoji�ֶΡ�������Щ��Ч��ֱ�ӷ����� ���������Ǯ��ʵ�ܼ� ���������ý���Զ����������� ������ý���Ŷӡ��������������û���һ������ 500 �C 3000r�����ƵĹ������������� 5000+���ܶ˾��ʵ��ȱ�ľ���Ч�ʹ��ߡ� �����������ĺ��ȣ� |

|
|
03 Openclaw + �����Զ����ϼ���Ʒ �ܶ�������������ʹ���ǣ��ϼ���Ʒ̫�鷳�� ����ÿ����Ʒ�ı���Ҫ�ģ�ͼҪ��������ҲҪ�ġ������Ҫ�ϼ� 1000����Ʒ�� ����Ҫ������ ���� Openclaw ֮���������̶������Զ�����ɡ� Openclaw�����Զ�ץȡ1688��Amazon��Shopify�ֻ���ƴ������Ʒ��Ϣ������ͼƬ�������۸����ȫ�������Զ�ץ�� |
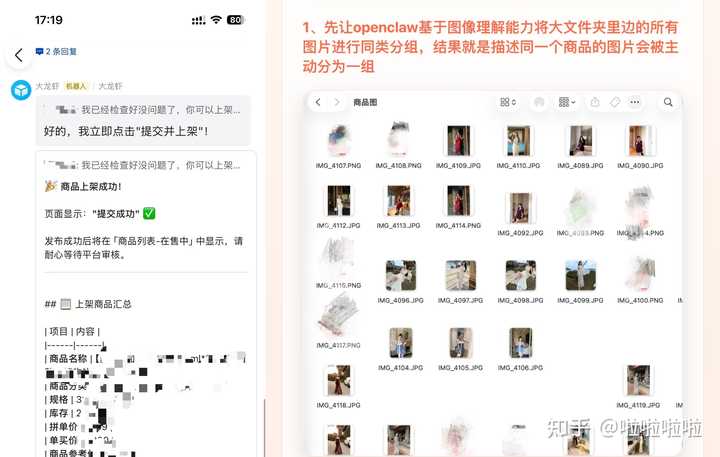
|
|
����ȡAI�Ż���Ʒ���⡢������Ʒ���������Ʒ���㡢ʹ�ó���������˵���Լ���Ʒ������Щ��Ϣ��һ����Ʒ����ҳ����һ���Ӿ������ɡ� ��ؼ�����Openclaw�����Զ�������̨���ϴ�ͼƬ����д���⡢��д�۸� �Լ����ÿ�棬Ȼ���Զ������� ���������24Сʱ����Ͷ��˲����𣿣� ֱ��ʡȥ����Щ�����ظ��ԵĹ������ܶ�羳���Ҿ��������ַ�ʽ��һ���ϼܼ��ٸ���Ʒ��Ч�ʷdz��ֲ��� �����Ҳ����һ���������Զ��������壬������֪��ô��ʼ�����Ը������������������openclaw�������Ź�����ҵ��Ŀ���������Ը������ա� ��Ʒ�������ǿ��Է���ʳ��~ ��������ҷ������ˣ���Ҫ��ͬѧ������ʦ����ֱ����� ������ ��??openclawֱ����???AI������+AI��ҵ+ʵ�ٴ��� ��0.00������ȡ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
" style="display: none;"> ����Ҳ�ܿ���������д�ú���ϸ���������Թ���ͦ�����IJ��Ƽ���ҵģ� |
|
|
��� �ܶ�������һ���� AI �ξͻ���ã��ø��ӻ�Ҫ���Ρ� ��ʵ���ϣ� ����ѧ�κ�һ����֪ʶ�������ǿ����ο���Ƶ������ʦ���������� �ҿ��������˵����Ǯ�� AI������Ŀ���ܼ� ����ֻ��һ���£��Ǿ������Ч�ʡ� ˭���� AI ��һ�����飬���ø��졢���ø��ࡢ���ø����ˣ�˭����Ǯ�� �� Openclaw �ļ�ֵ������������ǵ����� AI�� ���ǣ�AI�Զ���ִ�й��ߡ� ������ܰ�һ����ҵ���̲������Ȼ�� Openclaw �ܡ� �����͵��ڣ�ӵ����һ̨�Զ�Ǯ������ �����ƪ�����а������ǵ� ����� + �ղء������һ���������������Ǯ���淨���� ����Ȥ�Ŀ��Զ�һ���� |

|
|
������ ��û�������������һ�����߰� |
|
�и������˰� OpenClaw װ�� MacBook������һ��ר��Ϊ�ݶ��а��̶��Ƶ� Skills���Ӻ� HubSpot CRM��������ҵר���� SOUL.md��Ȼ��ֱ�Ӽĸ��ͻ��� ��磬AI Ա���ϰࡣ �շ� 5000 ��Ԫһ̨������ weekly ֧�֡� ��ȻMacbook����ҵ��������Dz��еģ������һ���ܸ�רҵ���豸�� �������Ŀ������ RoofClaw�����������Ѿ����� 180 ����Ԫ�������� 360 ����ݶ��а��̡� ��һ���ˣ�ȫ�� AI Agent �г� 2025 �� 76 ����Ԫ���긴�������� 49.6%��2033 ��Ԥ�Ƶ� 1830 ����Ԫ��ȫ��羳�����г�����ͻ�� 4 ������Ԫ���й����ڵ��̱ƽ� 3 ��������ҡ� ���������ڼ��г��Ľ���ش������� AI Agent ��羳���̹�˾�ɻ�����£����ع�����һ��ǧ�ڼ��ķ����г��� �����ڣ�����г�����û��ϵͳ������ �����ջ��� AI ��ȼ�� �������ܵ� NGS AI�羳���̴����˵����仰�� ���Ŵ̶���������������Ŷ����ڵ���ʵ״̬�� ?? ȫԱ����Ǩ�Ƶ����飬��������� OpenClaw�����й����Ի���AI ���Ա�ͬ����������֪ʶ��ת�� Skills���´�ֱ�ӵ��á����ѭ��������֮����֯��ÿһ�ζԻ����ڸ� AI ιȼ�ϣ�����Խ��Խ�������ҵ������ҹ�˾����ÿһ�������ҵ���� |
|
|
�����һ�����һ�� OpenClaw �羳���̱��Żᣬ���Ķ���������ҵ����ˡ� ���ҷ���һ���¡�����Ҷ� OpenClaw ����ҵ�����˵������������Ա�ҵ������� ��ʵ�羳��˾�Ĺ�������һ�㲻��ҵ��С��Ա����ʧ��֪ʶ�ϲ㡢�����ͺ��˹������ң�ÿһ�����ܸ��һ�����������Ĺ�˾�� ����Ͱ������Ŷ���ʵ���ܵļ�����������������ǧ���г�����Ҫ��ô���� |

|
|
01 ����Ⱥ������Ϊ֪ʶ�⣬��ת��Skills ��˾�������Գɱ����ǹ��ѣ�����Ա������ɵ�֪ʶ��ġ� һ�������������Ӫ��ְ����֪����ƽ̨���ȹ��Ŀӡ���Ӧ�̵�Ĭ����ȫ�����ˡ� ��һ���˴��㿪ʼ���ٲ�һ�顣���ѭ��ÿ�궼���ظ��� �������ڵ���������ǰ��˵�����������Ҳ�����õĻ�����ʵ˵��һ���ż�û�С� �Ҷ���ֱ�Ӹ�Claude��ͨ�� |
|
|
��ʾ�ʣ� 02 �� AI ��������ҵ���е��Զ������� �ܶ�羳��˾�Ѿ���һ�����ܵ��Զ������̣�n8n ������������ RPA�����ƽű��� ��Щ�����ɻ���ȣ����˴�֮���ǹµ���A ������Ҫ��Ҫ���� B��ȫ���������� OpenClaw ���ʺ����ľ��������ȴ��ԡ� |

|
|
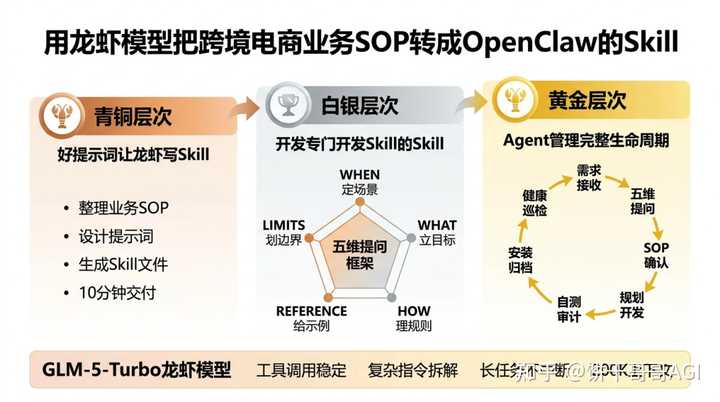
�������´��Ĺ۵� ԭ���������ģ� ?? OpenClaw Gateway ԭ��֧�� Webhook ���ա��� openclaw.json �� hooks �↑�� webhook����� token��n8n ����������һ�������ͨ�� HTTP POST �Ƶ� OpenClaw �� /hooks/agent �˵㡣OpenClaw �յ�������һ�� isolated session �� agent turn���ж���һ���Ǽ����ƽ�������Ҫ�˹����룬�쳣��ʱ�����ɴ������鲢���͵�����Ⱥ�� �����滻���й��ߣ������������һ���˼���ĵ��Ȳ㡣 �ο����÷����� ��һ������ openclaw.json �↑�� Webhook�� �ڶ�����n8n ������ĩβ��һ�� HTTP Request �ڵ㣬POST �� OpenClaw�� ���������� AGENTS.md ��д������ж����� 03 ҵ�� SOP ������ Skills�����������Ļ��Ǻ� �������ǰ�췢������ ����ô�ѿ羳���̵�ҵ��SOPת��OpenClaw��Skill ����Ͳ���������������Openclaw�����ʣ���ҵ��SOP��������� |
|
|
04 ���ϰ�ع顸����Ҫ���ߡ������ �����Ҽ������羳�ϰ�ȵĿӣ�ÿ�컨һ��Сʱ�����ֺ�̨���ݣ�����Ҳû��ʲô���ߡ� ���ݱ���û�м�ֵ�����������ľ��߲��м�ֵ�� �����Ŷ�����һ�������°�ľ��������� ������� ?? ��������ѷ��� API������վ GA4�������ά����ÿСʱ�������ж��쳣��ROAS ������ֵ���˿��ʳ��ꡢ��治�� 7 ���������������͡�����ʱ���Ĭ��ÿ���� 9 ��һ�ݵ��ռ��Ѿ������ۺͽ��鶯��������Ҫ�ϰ��Լ��㡣 ����ҵ�����ݣ���� Agent ���ܽ����Ŷӳ�Ա���ձ��ܱ����Զ������ؼ���չ�Ϳ��㣬�ϰ���鿴���IJ���һ�����֣�����һ�ݽṹ���ġ���Ҫ���ע���¡��嵥�� �ϰ�������Ҫ��ֻ��һ����Ϣ�������ļ�����Ҫ���������� ���÷����� ��һ������������Ѳ��� Cron ������ isolated session������ʱ����������� �ڶ������� AGENTS.md �ﶨ���쳣��ֵ�� 05 �� Agent Э������Ҫһ��������� Agent ���������������һ�������� ��֮ǰд��һƪ���£���OpenClaw��羳�����Ŷӣ�5��AIԱ������ͨȫƽ̨���� ���ܶ��˿��˶� Agent �Ľ̳̣���һ��Ӧ���Ǹ������� Agent��һ����ѡƷ��һ���ܹ�桢һ�������ݡ�һ���ܴ��ˡ���Ȼ��������ϵͳ�����ܲ������� ��������ģ� ��һ��û�ж��Ρ���� Agent ���ɸ��ģ�˭Ҳ��֪����������ʲô���ý��ӵIJ����ӣ��û㱨�IJ��㱨�� �ڶ������ɳ�ȥ�ղ�������OpenClaw �� sessions_send �и��������ƣ������λظ��ij�ʱֻ�� 30 �룬���˾Ͷ��ˣ����� Agent ��Ϊ�Է�û�ɻ ������������̫������©��ÿ�� Agent Ҫ������ workspace���� IM �˺š��� A2A Ȩ�ޡ��� Session �ɼ��ԣ���һ��������·���Ƿϵġ� ��ȷ�������Ƿֽ����� ��һ��һ���� Agent + SubAgent ģʽ ����Ҫ������� Agent����һ���� Agent����������ͨ�� sessions_spawn �ɸ� SubAgent �ں�̨�ܣ��������Զ��ش������ģʽ�������90% �ij������á� �ζ�����Ҫ����ͬʱ�Ի�ʱ���϶� Agent ������Ŷ���������Ҫͬʱ����ͬ�� Agent �Ի���������Ӫ����Ӫ���֡��ϰ��Ҿ������֣�����ʱ�����Ҫ�����Ķ� Agent ·�ɡ� �ؼ����������£� 1. �������������룺ÿ�� Agent �����ж����� workspace���� openclaw agents add ���������Ҫ�ֶ���Ŀ¼��2. A2A ͨ�Ű��������� openclaw.json ����ʽ���� agentToAgent�� { "tools": { "agentToAgent": { "enabled": true, "allow": ["lead", "ops-assistant", "ads-assistant"] } } } ## Э���� ### ί������� - �յ� sessions_send ���� { status: "accepted" } ������������������������һ���� - �������Ƚ������֪�û�����ί�ɸ� @[����ID]���ȴ��������Ȼ�������ǰ�ִ� - ������ɺ��ͨ�� sessions_send �ش������� ### �ӵ������ 1. ������Ⱥ���� message ����֪ͨ�û��ѽ��֣���Ϣ��ͷ @����AgentID�� 2. ִ������ 3. ��ɺ�����Ⱥ��㱨�����ͬ�� @����AgentID�� 4. ͬʱ������� sessions_send ��������ظ�ί���ߣ����ѶԷ��������� 3. ˫�ػ㱨Э�飺��ÿ�� Agent �� SOUL.md ��д��Э�������ʱ���⣺����������ͨ�ŵ� Agent �б��� ��ҵ��ص����һ�������豸 �ܶ����������豸������²������� �����û�����棬Mac Mini ����һ̨�����Ժõ� PC�����ƶ�ģ�� API����ȫ���ˡ� ����ҵ�Ͳ�һ���ˡ���������Ƽ��豸����Ҫ�����ೡ������˵��������Լ��Ժ������� |

|
|
��һ�ࣺ���ݲ��ܳ��ŵ���ҵ�� �ܶ�羳��˾���������ݰ����ͷ��Ի���Ա����ͨ����Ӧ�̱��ۡ�������ݡ���Щ�������ȫ���ƶ� API�����ݾ��ڱ��˵ķ����������ˡ�һ���漰�����鱨���۸���ԡ�KOL ��Դ��������ʲ����ƶ˷��������ϰ�ܲ����� �����Ѿ��ھ��治Ҫ�ڹ����豸�ϰ�װ OpenClaw�������ǰ�ȫ���ա�˽����ҵ��Ȼû�����ǿ��Ҫ��������Ȩ��������ʵ���ڡ� ���ೡ�������ز���ģ����Ψһ�ɾ��Ľⷨ�� |

|
|
ͼ������ ���Կ��� ���ƺ��� �� HY50 ��������������Լ۱���ߵ����ŷ�����500GB �������ڴ棬�� Qwen3 235B Q4 ���� MoE ��ģ��û�����⣬30 ·�����㹻����һ����С�Ŷӵ��ճ� AI ���ã�HEYI ������������� CPU �ڴ�������ӵ����£�����Ԥ����ʮ��Ԫ���� �ʺϣ�20 �����µĿ羳�Ŷӣ��������������ݲ����š�������ͨ OpenClaw �������������� �ڶ��ࣺ�ŶӲ���������ͬʱ���� Agent ����ҵ�� һ̨����ͬʱ�� 20 ��Ա���� OpenClaw ����ÿ�� Agent �Ự���ڵ����� Agent�������Ķ������� token�����ڴ�����Ͳ���������Ҫ����ȫ������ͨ�豸�ܳŵġ� |

|
|
ͼ������ ���Կ��� HY NV4-6000 ���Ŀ� NVIDIA RTX 6000 Pro��384GB ��·�Դ棬128 ·����ʵ�⣬32 ·�ճ��칫�˾������� 192K��������õĺ��ļ�ֵ�ǣ���˾���� Agent ����������һ��˽��������������Ȩ��ȫ�Կأ����ڡ����Ϲ�ȶ����ݰ�ȫ��ǿҪ��Ļ��ڿ���ֱ���ܡ� �ʺϣ�50 �����ϵĿ羳��ҵ���������ͬʱʹ�� OpenClaw����Ҫͳһ��˽�� AI ������ʩ�� |

|
|
ͼ������ ����ǹ�˾�� AI ��̨��Ҫ��ȫ�� Agent ��Ƶ���������ģ�Զ���ҵ��������Ҫ�� HY NV8-6000 �ˣ�768GB ��Ѫ�Դ棬֧�� Qwen3.5��GLM 4.7���콢ģ�͵�ԭ����������������ģ������� 2000+ tokens/s��������þͲ���һ�����ŵ������ˣ������ҹ�˾�� AI ���������� ����ҵ����OpenClaw���������û�и�ͷ�� ���漸����������һ����ͬ��ǰ���Ҫ���˰�������á� Ŀǰ�����������Ǯ��ģʽ�������Լ��� OpenClaw ȥ���£����ǰ������� OpenClaw Ȼ���������Ѿ��з����̵��η�����Ѿ�������Ԫ����ҡ� ���ģʽ������ʵ�ܼ��羳��˾�ϰ�֪���Լ���Ҫ AI������֪������Ҫ��ʲô����ô�䡢���֮��ά��˭�����������Ϣ���Գƣ����Ƿ����ֵ���ڡ� ?? ��������һ���Կ��伴�õ� OpenClaw ���ã�SOUL.md д�ɷ�����ҹ�˾�Ļ������裬����ҵ�� SOP ת�� Skills ���ϣ������ n8n �ĽӿڽӺã�Cron ����������ϣ�ֱ�Ӳ����� HEYI Ӳ���ϼĸ��ͻ����������Ų��� ��磬AI Ա���ϰࡣ ����羳���̶��Ʒ�����г��۸��� 500-2000 ��Ԫÿ����Ŀ����ҵ���������ڳ�Ϊ OpenClaw ��̬����������������Դ���������г��������ֱ�����ϼ������ǿհס� �羳�������Ȧ�ӣ���ҵ�������˺ܶ࣬�� OpenClaw ���õ��˻����٣����߶������˼���û�С� ����һ����ʵ��ʱ�䴰�ڡ� |
|
�������磬�ҵ�AI�������ҷ���һ����Ϣ���һ�����˯�� ���Ժ����㿪���飬����һ����Ϣ�� ������ʦ���ռ�ͻ�����ţ�������ɫ�й������ʣ���������Ҫ�㣬��Ҫ���𣿡� ����Ϣ�IJ������ࡪ�����ҵ�AI������СM�� ��֪��������AI��ý�壬֪����Ҫ��һʱ������ҵ��̬�������ţ���������ʲôʱ�������ڹ����� ����Ҫ���趨���ѣ����Լ��жϡ��Լ�ִ�У�������Ҫ���Ƹ��ҡ� �ⲻ�ǿƻõ�Ӱ�� ����������ÿ�����ʵ��� ����һ�У���Դ��һ���� OpenClaw �Ŀ�ԴAI��Ʒ�� һ����ͳAI vs AI Agent��һ��֮�����֮�� �ܶ������ң���ChatGPT��Ҳ�ܻش�����������OpenClaw��ʲô���𣿡� |

|
|
��ͳAI vs AI Agent�Աȣ� ������ʽ��һ��һ�𣬱�����Ӧ �� ������⣬�Զ�ִ�м����������Ի����������� �� ���ڼ��䣬Խ��Խ���������������ּ����� �� ���Ӷಽ��������Э��������һ������ �� ��Agent�Ŷ�Э�����ƻ���ͨ��ģ�� �� ר���˸�+ר������ ��˵����ͳAI�ǡ����ߡ���AI Agent�ǡ�����Ա������ ��й��ߣ����Ŷ���������Ա������������˼��������ִ�У���������˯�ŵ�ʱ�����ɻ�����ҵ������Ŷӣ���СM����СK����СC |
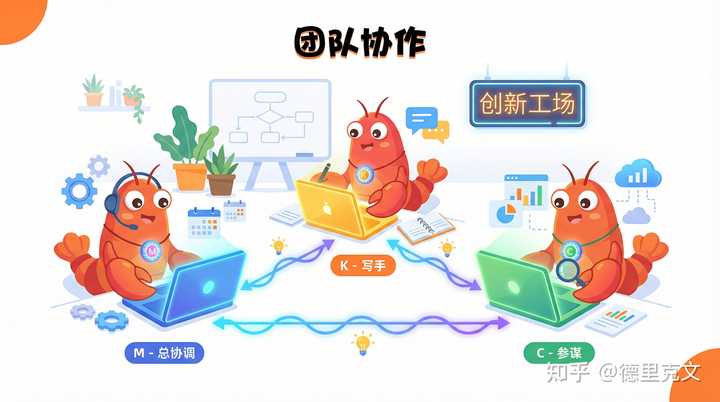
|
|
��OpenClaw���ҡ���������AI����������ҵġ���Ϻ��ѧС�项�� ?? ��СM �� �鱨Ա+��Э�� ÿ������9:00���Զ�ɨ�� Instagram��TikTok��Pinterest��Twitter �ĸ�ƽ̨��AI�ȵ��������ȵ�����͵�����Ⱥÿ��18:00ִ��ȫ�鸴�̣����ܲ���������������ݱ��֣������쳣�������� ?? ��СK �� ����ִ���� ��ⱬ�����£������ṹ�����ӡ������ƽ����������������������ȼ�¼���������Ż�SOP ?? ��СC �� ��ı�� ��ؾ�Ʒ��̬��ÿ�������Ʒ�ձ��ṩѡ�⽨�飬����������ά��AI���߿⣬�������� �����˻���Э��������ල�����ң�ֻ��Ҫ�ڹؼ��ڵ������ߡ� ���ܵ���ʵЧ���� ��СM����BվAI��Ƭ�����ӡ���������1000��������������AI��Ƶ����ȫ�汬������ѡ������СK���������������µij����ܺ�������ѡ�����СC�����˾�Ʒ�˺ŵ����ݶԱȣ���ѡ���жϸ������� ԭ��������·��Ҫ��һ���˻�һ��ʱ�䡣���ڣ���ֻ��Ҫ�����ľ��ߺ���ɫ��������СM��һ�죺AI Agent����ô������ |
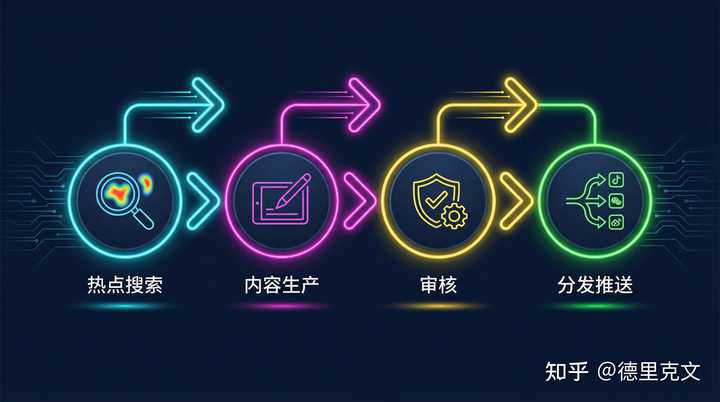
|
|
09:00 �Զ�ɨ����ƽ̨�ȵ㣬���������ͷ���Ⱥ10:00 ���������ȵ㣬�ж���Щֵ��д����Щ���Ե�14:00 ����СK�����ݽ��ȣ���Ҫʱ������������16:00 ���¹��߿⣬��¼�����·��ֵ�AI���ߺͶ�̬18:00 ȫ�鸴�̣����ܵ������˲�����д����־�ļ�24:00 ���ش���ҵ��̬���ж���Ҫ�ԣ������Ƿ�����֪ͨ����ʦ �ⲻ�����趨���������ѡ������ǵ�СM�����ҵ�ϰ�ߡ��ҵ������Լ��жϡ��Լ�ִ�еġ��ġ��ӡ����Կ�ɡ�����AI����������������Ѿ������� ��Щ���ڻ����ֶ�ˢ�ȵ㡢�ֶ��������ݡ��ֶ��ظ���������Ĵ����ߣ����Ѿ�����Щ����AI���ˣ�һ����վ�ڷdz���ͬ��λ���ϡ� �ⲻ��Σ���������������ڷ�������ʵ�� ���߿�ʼ�ö�AIЭ��ϵͳ�IJ��������ݷ���Ƶ�ʺ�ѡ������ٶ������ü����� ��Ϊ���Dz�����Ҫ��80%��ʱ������Ϣ�ռ��ͻ����������ˡ� �塢��ͨ�˸���ô��ʼ�� ����ܻ��ʣ�����û�м�������������OpenClaw�𣿡� |

|
|
���ǣ����ԡ����ұ��������м� ��һ������ȷ��ĸ�Ƶ�ظ����� ÿ����ȵ㣿 ÿ��������Ʒ��Ϣ��ÿ��������ѡ�⣿ ��Щ������AI Agent���Խ��ֵġ� �ڶ�������Agent�趨�˸��ʹ�� ��OpenClaw���ֻ��Ҫдһ�Ρ������������������֡��Ը���ְ�𡣾����Ҹ���СMд�ģ� �������ҵ��鱨Ա����Э����ÿ�����ĸ�ƽ̨��AI�ȵ㣬���ͼ�ͳ��С����ȡ��� ��������������Ĺ���ƽ̨ OpenClawԭ��֧�ַ��顢������Discord������Э��ƽ̨�� ���Agent���ԡ������Ĺ���Ⱥ���������ͬ��һ��Э��������ֻ���ʴ�����ˣ��������������͡��������ѡ������㱨������ͬ�¡� ���IJ�������Ĺ��̱���������� ��AI�������Ĺ��̣�������õ���ý���زġ���ȵĿӡ���������·����¼�������Dz��컯���ݡ�������AI����ʵ�������ݵ��˺ţ���˿�����ձ�����������ࡣ д����� ����˵��AI��ȡ������Ĺ����� �ҵĿ����ǣ�AI����ȡ���ˣ�������AI���˻�ȡ�������õ��ˡ� OpenClaw���Ҵӷ�����ִ�й����н�ų������Ѿ����۽��ڴ���;����ϡ� ��������7��24Сʱ���ߵ�����Ա���������Dz����ۡ������������ᱧԹ���賿�������ҵ��̬��������������Ҫ��Ҫ���� ���ң�ֻ��Ҫ���Ǹ���ָ�Ӽҡ��� �����Ҳ��ӵ�������Լ���AI�Ŷӣ�����ȥ���� OpenClaw�����߹�ע�ң��һ��������������Ϻ��ѧС�����ʵʵ�����顣 ��ס�����ʱ������ϡȱ�IJ���Ŭ����������֪�� ���㻹���ֶ������ظ�����ʱ����ľ������ֿ����Ѿ�����24Сʱ���ߵ�AI������ �����ڲ���һֱ���š� ����������Ϊ�ҵ�����Ա������OpenClaw����д����ɣ�����������ܼ���ͼ����MiniMax Agent���ҽ�����������ɫ��) |
|
|
| [�ղر���] �����ر��ġ� |
| �Ƽ� �������� |
| ���ڶ�����ˮƽ������Σ� |
| ��ο��� DeepSeek δ�� 7 ����Ѯ���� V4 �� |
| �������GPT5.6Ϊ�����ܷ������ף������ھ� |
| Kimi ��ģ�� K3 �ܷ���ѹ ClaudeFable5 �Ƕ� |
| ��ο��� 7 �� 22 �� DeepSeek �ͻ��������� |
| OpenAI �����˳� Kimi ��Դ�Ǽ������壬���� |
| OpenClaw����ͷ�� |
| Ϊʲô��Щ�û���Ը�����棬Ҳ��ԸΪ������ |
| ��ο���DeepSeek-V4��ʽ�淢����Ʊ����£� |
| ��ο�������һ���ڴ���openai����Ҫɱ���� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
|
��������:
��ӰƱ��
����Ȧ
����
����
����
�����
ӡ��
�ɼ�
��س
����
��ˮ
��Ǯ�ҽ���ר��
����
˫ɫ��
����ĸ��
����
ƹ����
�й�Ů��
����
nba
�г�
�ܲ�
����
���
��ɫ
�Ϻ��п�
80��
����: ���� �����ֶ� ������ķ�ȴ� �ʼ������� ����ͼ˹ ���� ����� ���� �ﰺ ����ʥ�ն��� ���� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ֪ʶ�� |